Chat:World/2021-05-25
NguyenThanhTam: fuck u all
NguyenThanhTam: đụ mẹ tụi mày
Riku5720: anyone join escape on steam house?
ZarthaxX: everyone is ded rn Riku5720
ZarthaxX: not the best time
Riku5720: yea
Chainman: :rofl:
derjack: good morning
![]() Roxxum: its 4:43pm lol
Roxxum: its 4:43pm lol
scareware047: lies
Mizt: hm
Mizt: :fish:
Mizt: how to add friend
derjack: follow them
khaleo: follow me
HoaiDien: ?
khaleo: doge coin to the hell
Roxxum: someones upset they havn't been mining dogecoin since 2014
Roxxum: its ok. i cashed out 77 bitcoins in 2014 when it jumped up to $20 USD per coin
Roxxum: sad times indeed
Roxxum: $200*
![]() Nixord: I wonder if Shiba Is and Doges will go to the moon in terms of price...
Nixord: I wonder if Shiba Is and Doges will go to the moon in terms of price...
Roxxum: from an economic stand point, doge's unlimited supply will hinder its ability for exponential growth. But with all cyrpto coins, its true value will always be directly tied to its real world uses
Roxxum: so doge does has potential for large growth in value. but i dont think it will ever reach eth or btc levels of value
Roxxum: assuming bitcoin remains as an accepted payment for things people actually want to buy (no matter what that actually means), bitcoin haters will be throwing up in 5-10 years time when its value is 100's of thousands of dollors a coin.
eth i actually dont know what to think. moving to proof of stake is going to shake everything up. i dont know where it will land. your average miner is going to be very upset, and may cash out? i dont know
![]() Nixord: What about Shiba Inu coin?
Nixord: What about Shiba Inu coin?
Roxxum: its such a low value coin, that percentage growth doesnt mean anything right now. as with all coins, it will depend on its real word adpotion for longevity and value. so who knows
Roxxum: you have to remember, the stock market is basically educated gambling, and thats a market with real companies with real cash behind them
Roxxum: cyrpto is even more volitile, and relies soley on real world uses to obtain value. there is no physical object behind it.
![]() Twi9630: This code is not working for higher case levels can anyone acknowledge me what modifications are required
Twi9630: This code is not working for higher case levels can anyone acknowledge me what modifications are required
![]() Twi9630: http://chat.codingame.com/pastebin/adc6c918-5724-4f97-80bb-ed946e996984
Twi9630: http://chat.codingame.com/pastebin/adc6c918-5724-4f97-80bb-ed946e996984
nocna.sowa: Memoization
derjack: or make fibonacci non recursive
![]() mod6013: fart
mod6013: fart
Mizt: hm
![]() BOBO124: helllo
BOBO124: helllo
![]() BOBO124: how I play this game
BOBO124: how I play this game
![]() mod6013: while true do end
mod6013: while true do end
![]() BOBO124: everyone can help me
BOBO124: everyone can help me
![]() BOBO124: everybody
BOBO124: everybody
![]() BOBO124: ı want to play coding game
BOBO124: ı want to play coding game
![]() BOBO124: but ı don't
BOBO124: but ı don't
![]() BOBO124: why nobody can't help me
BOBO124: why nobody can't help me
![]() BOBO124: helllllooooo
BOBO124: helllllooooo
![]() BOBO124: :rage:
BOBO124: :rage:
![]() BOBO124: :angry:
BOBO124: :angry:
Roxxum: lol
![]() BOBO124: wtf
BOBO124: wtf
Roxxum: if nobody responding within 30 seconds upset you that much, i have news for you son
Roxxum: life is going to eat you alive <3
![]() BOBO124: ı love you baby
BOBO124: ı love you baby
![]() BOBO124: roxxum :lips::heart_eyes:
BOBO124: roxxum :lips::heart_eyes:
![]() ArtLiteracyStory: :eyes:
ArtLiteracyStory: :eyes:
![]() BOBO124: wtf
BOBO124: wtf
HTierney703: whats going on here
![]() mod6013: fart
mod6013: fart
![]() Alejandro127: no idea
Alejandro127: no idea
HTierney703: goyim
![]() mod6013: fart
mod6013: fart
![]() Nixord: lol
Nixord: lol
![]() Nixord: Also sorry and thank you Roxxum. Imma go to bed now (6:10 AM here) nighty night everyone ^^
Nixord: Also sorry and thank you Roxxum. Imma go to bed now (6:10 AM here) nighty night everyone ^^
![]() BOBO124: nighty night to you
BOBO124: nighty night to you
![]() BOBO124: ı love everyone end nobady
BOBO124: ı love everyone end nobady
![]() BOBO124: and*
BOBO124: and*
![]() BOBO124: nobody*
BOBO124: nobody*
![]() Nikolaou1982: should you be living in antartica that statement could be trivially true
Nikolaou1982: should you be living in antartica that statement could be trivially true
![]() Unnabhv: hi
Unnabhv: hi
HTierney703: why was i kicked
HTierney703: :disappointed:
![]() ArtLiteracyStory: :melon:
ArtLiteracyStory: :melon:
KiwiTae: HTierney703 it happens to the best
HTierney703: solid :muscle_tone5:
RageNugget: hi is there a way to resume clash challenges? sometimes i'd like to finish my stuff
derjack: for clashes, no, there is no resume
![]() ahhhhhhh12345: senx
ahhhhhhh12345: senx
![]() ahhhhhhh12345: yo
ahhhhhhh12345: yo
derjack: :unamused:
HTierney703: yuo r such a sussy baka
HTierney703: :worried:
CWinter703: amongus
doogh: dont even know what to do for clashhes and dont even know how to porgam but screwit im gonna do one.
doogh: smh
HTierney703: yeah its super hard
HTierney703: like mogus
CWinter703: mogus?
HTierney703: yes my good fellow
HTierney703: *mogus*
HTierney703: MOGUS
HTierney703: :regional_indicator_m::regional_indicator_o::regional_indicator_g::regional_indicator_u::regional_indicator_s:
derjack: Magus the moderator?
HTierney703: no my dear friend
HTierney703: mogus
HTierney703: not Magus
HTierney703: MOGUS
HTierney703: :regional_indicator_m::regional_indicator_o::regional_indicator_g::regional_indicator_u::regional_indicator_s:
KalamariKing: Clashes are the best
But damnit my rank is slipping
KalamariKing: Actually there is a pseudo-resume, once the clash exits no but if you accidentally left the page, go back to it and contine
KalamariKing: continue*
AntiSquid: what the hell is a mogus
KalamariKing: I believe it is a play off of "amogus" which is a play off of "among us"
Ragimov: amogus
lfourner: sus
KalamariKing: Can we... just... not
lfourner: sorry
KalamariKing: thanks ;)
KalamariKing: just hope as a site, we have a collective braincell count of more than 14
peerdb: sorry im not helping KalamariKing
Westicles: huh, my default submit after 3 months decided to climb 2 leagues in a day
derjack: huh
Uljahn: in kotlin?
Westicles: c++ code ala mode
Westicles: just a cout<<"WAIT"
derjack: to best move is not to play
StevensGino: I often see my default code go into Legend league also
KiwiTae: ><
StevensGino: If you don't believe it, you could try my technique
StevensGino: Just close your eyes and imagine
KiwiTae: StevensGino i was gonna say u got no bots in legend leagues
KiwiTae: hehe
StevensGino: In my mind, I see a lot of my bots in legend.
StevensGino: :D
derjack: thats some serious mental illness
StevensGino: that's a way to creativity, man
StevensGino: few people here
BrunoFelthes: Any tips to beat the TTT gold boss?
Westicles: teccles?
BrunoFelthes: what is teccles?
Westicles: beats me
StevensGino: what is TTT?
BrunoFelthes: tic-tac-toe
derjack: you mean UTTT?
BrunoFelthes: yes
derjack: MCTS?
StevensGino: use my technique, you can do anything
BrunoFelthes: what is your technique StevensGino
StevensGino: "
Just close your eyes and imagine"
StevensGino: just kidding
derjack: oh youre 1st in gold. nice
BrunoFelthes: I'm using MCTS derjack... but it is not enough...
BrunoFelthes: yes, but with 1 point less than the boss :(
StevensGino: 1 point or 0.1 point?
derjack: do you use mcts solver? do you use winning moves in simulations if available?
BrunoFelthes: I need to find some weakness at the boss
BrunoFelthes: no, how to do it?
BrunoFelthes: what is mcts solver?
derjack: your simulation is totally random? missing sure win even if its 1-ply ahead?
BrunoFelthes: maybe it is what I need...
derjack: mcts solver - during expansion if you encounter winning node, the parent node is lose. if all siblings nodes are losing, then parent node is winning, the again grandparent node is losing
Uljahn: also varying the exploration constant may help
derjack: this way you can basck propagate proven wins/losses up
derjack: so solved loses wont be chosen again
BrunoFelthes: at my rollouts, it is full random... at my tree, if one node is winning, i remove all others children at this node
BrunoFelthes: hum... maybe i'm doing it wrong
BrunoFelthes: do you have any sample code that do it derjack?
BrunoFelthes: or article?
Uljahn: https://www.minimax.dev/docs/ultimate/
derjack: BrunoFelthes its alright. you can go step further and during backpropagation make the parent of the node losing one, or give it score -inf
derjack: maybe something like that will help https://github.com/jdermont/QtYavalath/blob/master/src/ai/cpu.cpp#L88
derjack: https://www.codingame.com/forum/t/ultimate-tic-tac-toe-puzzle-discussion/22616/104
BrunoFelthes: thank you
lukehewittvandy: hi
derjack: ohai
![]() TheBrutalBeast_a16: hi
TheBrutalBeast_a16: hi
MSmits: derjack, am I correct in assuming the xor examples all use batch-size = 1?
derjack: yes
MSmits: that could be pretty bad right? If i just do the same for TTT
derjack: why
MSmits: well, what I read about this is that it might not converge properly with a batchsize that is too small
derjack: mini-batch GD may have better convergence properties, but minibatch 1 (in other words, SGD) can converge too
MSmits: hmm ok
derjack: it was also to keep xor example simple. for batching you need to do... transpositions!
MSmits: yeah i wont get into that then. Just trying to figure out what is lacking about my TTT
MSmits: I tried some supervised learning too. Just all possible states from minimax with targets
MSmits: if I select 50 of them randomly, I am already having trouble predicting them all correctly
MSmits: 20 or so works ok
KalamariKing: ok ok how come we all started doing nns for oware and now we're all doing nns for ttt
derjack: error's increasing?
MSmits: just some are completely wrong
MSmits: +1 instead of 0
Riku5720: https://escape.codingame.com/game-session/Vci-ZnF-z1C-0Y4
MSmits: KalamariKing this is practice
MSmits: I've never done oware
MSmits: oware is harder than basic TTT obviously
KalamariKing: what kind of nn are you using MSmits
AntiSquid: where are you at with your NN MSmits? what exactly are you strugglin with
derjack: could be some fluke in the code
MSmits: getting it to work. I am using a basic MLP with one hidden layer and i tried 20 to 200 nodes in the hidden layer. Self play wasnt working at all, so now just trying supervised learning. If that works, ill go back to selfplay
MSmits: yes could be jacek
MSmits: just wanted to be sure it wasnt the batching thing
derjack: is error decreasing anyway?
PatrickMcGinnisII: A puzzle a day keeps the Dr. away
MSmits: it's learning fine for small samples
KalamariKing: are you batching?
PatrickMcGinnisII: laterz
MSmits: no
MSmits: batching is a bit hard to do manually apparently
MSmits: trying to do this without batching
KalamariKing: could be something with learning differently on small batches vs large batches
KalamariKing: e.x. right now, its just one batch, large dataset = large batch
MSmits: yeah but i am not using batches
derjack: in my experience batching isnt neccessary. i do it because this way its more paralelizable and faster
AntiSquid: what inputs / outputs did you usn for selfplay? something must be bugged in there, 1 hidden layer of size 200 should have done the trick @_@
MSmits: KalamariKing no it's a batch of 1
KalamariKing: right
KalamariKing: i get that
KalamariKing: but its still a "batch"
MSmits: in a different sense of the word sure
KalamariKing: so a large batch could learn differently than two or three smaller batches
derjack: can you share the network code? could be pm
MSmits: yeah, sure, sec
derjack: btw. does electric heater has 100% efficiency?
MSmits: https://pastebin.com/7S2HbHsV
MSmits: brb
AntiSquid: there's no system with 100% efficiency @_@
KalamariKing: but if its job is to be inefficient
KalamariKing: is it efficient
derjack: if everything goes into heat, thenm heater has 100% efficiency no?
derjack: eventually
AntiSquid: there are other factors to consider
AntiSquid: "Electric heaters are all considered to be 100% efficient, because they turn all the electricity they use into heat, but this does not mean they are cheap to run." oh well they are considered to be as such
AntiSquid: https://www.electricradiatorsdirect.co.uk/news/eight-myths-about-efficiency/
AntiSquid: point 4
derjack: MSmits what is the learning rate
MSmits: 0,01
AntiSquid: i am not sure about your backprop tbh
MSmits: me too
derjack: seems alright
derjack: i plugged xor inputs and outputs and it works
MSmits: cool
AntiSquid: try tanh instead of sig and run it for a while MSmits
MSmits: hmm
AntiSquid: xor can give positive results with a lot of things :D#
AntiSquid: and try without momentum at first
MSmits: yeah
MSmits: probably should make it simpler by removing momentum
derjack: have you tried one-hot yet
MSmits: this is one hot
MSmits: 27 sized input
AntiSquid: hard too read a bit unconventional compared to other py nn, thats why it looks weird
MSmits: board flipping
derjack: flipping?
MSmits: o becomes x when it's o's turn
MSmits: so player to move is always x
MSmits: what robo does in oware
MSmits: it's easier for me than using 54 inputs
AntiSquid: try without one hot encoding first, it should still deliver results and you can expand later
derjack: well nn could predict whose turn it is based on how many empty square there are
MSmits: that might be harder to fit though
AntiSquid: depends what rest of the code is . like what is it supposed to figure out
derjack: forget about flipping and side to move. lets put the board as is
MSmits: yeah but side to move is really important
MSmits: it makes the difference between +1 and -1
MSmits: as target
AntiSquid: only 1 output ?
MSmits: yeah
MSmits: value network
derjack: hmm
derjack: my value network is from perspective of 1st player only
AntiSquid: so NN evaluates each move ? or figures the square out for you ?
MSmits: derjack yeah mine too in effect
MSmits: because of the flipping
MSmits: do you mean you never made a TTT bot for player 2?
MSmits: AntiSquid yes it tries all moves
derjack: i just take the negative of the prediction as p2
MSmits: thats weird
struct: -1,1
MSmits: I mean if it's your turn and you can win
struct: you can see from his uttt bot
MSmits: the opponent might not be able to win from his side
MSmits: only draw
MSmits: so just doing negative is incorrect isnt it?
derjack: im contaminated with negamax thinking. in negamax you always have eval from perspective of 1 player. the other player will take minus of that
MSmits: what i do is try all (max) 9 moves, then look up from opponent perspective and take the move with the lowest value from his perspective
MSmits: i apply move and flip to do this
MSmits: after i flip it's opponents turn
jrke: how many possible states are there in tictactoe?(unique and valid)
MSmits: so can do the network forward thingy from his perspective and of the 9 options i pick the worst one
MSmits: my minimax comes up with 4120 jrke
MSmits: it's a full minimax
MSmits: and uses dictionary for transpositions
jrke: then my minimax is having bugs
derjack: 5478
jrke: it gives 5833 to me
struct: and symmetry right?
MSmits: yeah, but some states probably unreachable
MSmits: not symmetry no
jrke: saved in dict
derjack: 5478 reachable positions
MSmits: my minimax stops when there is a win available
MSmits: so thats why there's less
jrke: yeah my also stops if game ended either any win or no space left
MSmits: i dont include finished states either
derjack: even wikipedia says 5478 https://en.wikipedia.org/wiki/Game_complexity#Example:_tic-tac-toe_(noughts_and_crosses)
MSmits: i know, but I didnt need finished states and such, thats why 4120
struct: A more careful count, removing these illegal positions, gives 5,478.[2][3] And when rotations and reflections of positions are considered identical, there are only 765 essentially different positions.
MSmits: doesnt matter anyways, i test all my samples manually, the targets are good :)
MSmits: my prblems are with learning not minimax
derjack: https://github.com/jdermont/tictactoe-ntuple/blob/main/cpu.h#L150 you can see its taking the negative of value if cpu is PLAYER_O
MSmits: http://chat.codingame.com/pastebin/58e991f4-0482-4421-8e55-b9c4c2120312
MSmits: text is below board, bit confusing
derjack: oh
derjack: anyway id say the batching (or lack thereof) isnt the problem
MSmits: no, you've convinced me of that
MSmits: ohh, this is an ntuple bot
MSmits: your bot
MSmits: i saw that code before
derjack: yeah. the network could be interface to any nn stuff, but principle is the same
MSmits: i thought you did a NN as well
MSmits: well, i guess I am trying to do a perfect -1, 0, 1 classification. That's not possible with your method
derjack: maybe i will
MSmits: but you can still play a perfect game
MSmits: the reason it's not possible is that a value 1 game when it's player 1's turn is not value -1 when it's player 2's turn
MSmits: that's only true when both players can still win, for example
MSmits: player 2 may be fully blocked whereas player 1 still has a possible row of 3
MSmits: oh but i think i see why it works
derjack: its not what you say
MSmits: it works because states are never both p1 and p2
MSmits: because you can count the pieces as you said earlier
derjack: there is board, i take prediction from nn. if im O, i negate it
MSmits: yeah, but if you're O, that means a X state that looks like that does not exisrt
MSmits: so it's np[
MSmits: that means the flip is safe
derjack: is it tho?
derjack: so X made 1 move
MSmits: because when there are equal marks of either player, it's always X turn, when there's one more X, it's always O's turn
derjack: now flip - O made his move, im the X
MSmits: yes but the state has changed
MSmits: there's 1 more mark on the board
MSmits: different lookup
MSmits: so maybe I don't need to flip either
MSmits: as you said
derjack: alright
MSmits: it does make things easier
MSmits: and you didnt find weird stuff in my network code right?
MSmits: I use a sigmoid for input and tanh for output
derjack: no weird stuff
MSmits: cool
derjack: personally i use leaky relu for hiddens
derjack: http://chat.codingame.com/pastebin/280c3fe6-01c9-46ef-b3fc-ec910f615f33
MSmits: normal relu is worse?
derjack: this works
derjack: i dont trust anything that turns into 0 :v
MSmits: turns into 0?
MSmits: also this is not one-hot :P
derjack: ah right
derjack: relu is x < 0 => 0
MSmits: ah right
MSmits: yeah it works for me too, just a bunch of states and fitting them
MSmits: but if i use like 50 i get wrong predictions
derjack: anyway, perks of ML stuff. even if you have NN working, there are still some issues of what to put there and how to use the results
MSmits: yeah
MSmits: i have ideas for that, but prediction needs to work too. Will mess around a bit more :)
MSmits: i wonder how large the network really needs to be for this
derjack: your target is from perspective of current player always?
MSmits: currently yes
Notaboredguy: hi
derjack: i think the targets counter themselves somewhere
MSmits: if you mean what i shared, always look below the picture
MSmits: i do a stupid line break
derjack: no, in general
MSmits: how do you mean
derjack: im thinking of an example
MSmits: kk
derjack: almost the same board, the target is 1 if player X to move, then suddenly the target is -1 if player O to move. i know this happens in this game, but i wonder
![]() Error.exe: hello
Error.exe: hello
MSmits: you mean this kind of thing could be hard to train ?
derjack: of a situation when it doesnt. nearly the same inputs have completely different target
MSmits: yeah
MSmits: for sure that happens
MSmits: maybe TTT is actually not an easy testbed at all
MSmits: re curse said it wasnt good
MSmits: not sure why tbh
struct: should have went straight to csb
MSmits: no way
struct: :)
MSmits: I want boardgames :0
ZarthaxX: addict!
MSmits: :)
MSmits: Target: 0 Prediction: 0.9999976819865413
X X O
O O .
X X O
MSmits: this is completely off
ZarthaxX: :(
MSmits: thats whats weird. I mean it predicts most of the 50 samples correctly
MSmits: but when it's wrong, it's wayyyy wrong
KalamariKing: because of how nns work, wouldn't two very similar inputs give two at least somewhat similar outputs
struct: prediction should be .5 right?
MSmits: yeah
MSmits: struct no, it's -1, 0, 1
KalamariKing: X O .
O . .
X . .
struct: ah so 0
KalamariKing: X . .
O O .
X . .
MSmits: Target: -1 Prediction: -0.9521188307197405
. . X
. . .
O . O
KalamariKing: the first is a win and teh second is a tie, but they're very similar
MSmits: this seems an impossible board
MSmits: but this is actually player 2's turn, flipped so it seems it's player 1's turn
MSmits: and it's a loss
MSmits: because the other player wil win
KalamariKing: first who's player one and who's player two
MSmits: basically, the one who's turn it is, is always X
KalamariKing: x goes first in all the games I've played
KalamariKing: yeah thought so
MSmits: so, X is player two here
MSmits: but the lookup happens always for the person who's turn it is
KalamariKing: oh ok
KalamariKing: thats kinda weird but I follow
MSmits: and that player is losing in this case
MSmits: because he can block the row
MSmits: but then the other player can do a double row
MSmits: thats why target -1 and prediction almost -1
KalamariKing: you can make that a tie tho
MSmits: nope
MSmits: top left corner
MSmits: causes double row
KalamariKing: ah I see
KalamariKing: I was going for middle center
MSmits: ahh ok, yeah then it ties
MSmits: anyways, the targets are good and predictions mostly good. But not getting 100%
KalamariKing: well I don't think its gonna
MSmits: and when it's off it's very off
KalamariKing: if its not learning then you don't have enough neurons
KalamariKing: do you have learning dropout?
MSmits: i use 200 for these 50 =/
MSmits: 200 hidden neurons
KalamariKing: yeah
MSmits: for 50 samples
derjack: nah, it should overfit anywayu
Uljahn: could be too much neurons
KalamariKing: yeah thats a lot
KalamariKing: try adding dropout to the hidden layer
MSmits: umm, it's not that easy to add stuff with completely manual network :)
MSmits: not using libraries
MSmits: just plain python
KalamariKing: oh i thought you said you were using tf?
MSmits: will do later
MSmits: i was hoping i could do TTT without TF :)
KalamariKing: pure python networks are slow tho
KalamariKing: tf is built on c++
MSmits: i dont mind slow if it's just gonna be practice
struct: he wants to understand it first
MSmits: yes
KalamariKing: ok true
MSmits: but i might have underestimated the task
MSmits: because TTT seems so easy for a search algo
MSmits: it's not the same as fitting 4 xor states :)
KalamariKing: you could add every single game state and every possible move :eyes:
MSmits: already did
MSmits: i took 50 samples out of that
MSmits: thats what this is
MSmits: btw i dont do move output, just value
KalamariKing: so then is that 50 random samples? or are they all similar
KalamariKing: what does your output look like then
MSmits: random out of 4120 boards reachable by a minimax that stops when it sees a win
MSmits: just a -1,0, 1 value from a tanh activation
KalamariKing: what does that correspond to in-game
MSmits: if i would use the network, i would try all 9 moves
MSmits: do a network.forward
struct: MSmits maybe you can check this article, it uses tf though
MSmits: and pick the worst position from opponent perspective
struct: https://medium.com/@carsten.friedrich/part-5-q-network-review-and-becoming-less-greedy-64d74471206
struct: it has like 8 parts
struct: on ttt
MSmits: nice thanks
MSmits: I remember that one, it's way more useful for me now though, will read that again
jacek: and even they are struggling with ttt
KalamariKing: I'm gonna try this after class
KalamariKing: join the struggling-with-ttt-nns-master-race
MSmits: hehe
MSmits: there's a nazi phrase in there though, maybe a pick a different name :P
ErrorCookie: .(°_°).
KalamariKing: youve never heard of the pc master race
KalamariKing: its a joke
MSmits: oh, nope
KalamariKing: ah
KalamariKing: I see
jacek: https://www.reddit.com/r/formula1/comments/bnaceq/if_you_could_eliminate_a_race_within_the_year/
MSmits: i thought it was an accident
KalamariKing: its a phrase in the pc community to say pc > laptop+console
MSmits: thats gotta be the worst miscommunication ever jacek :P
MSmits: ahh ok KalamariKing, it's true
MSmits: sometimes when a new console came out it was on par with PC, but never long
KalamariKing: yeah lol
KalamariKing: you got, like, 3090s pulling 14.8k frames per ms
MSmits: mmh you mean per second?
MSmits: that seems an aweful lot
KalamariKing: millions of frames per nanosecond
MSmits: a ms is a microsecond then>?
KalamariKing: ms=microsecond
MSmits: ah
MSmits: thats even worse
MSmits: how does that happen ??
KalamariKing: your 0,01 notation earlier says you're not from the states? it might be a US thing to say ms
MSmits: no, I am Dutch (my profile shows the correct flag )
MSmits: when i type too fast i sometimes use commas
KalamariKing: do you guys use decimals with periods?
MSmits: nope commas
KalamariKing: yeah I thought so
MSmits: 0,23 instead of 0.23
MSmits: it's annoying when coding
KalamariKing: its so weird seeing someone type like 1.000.000,23
MSmits: sometimes forget
MSmits: yeah, thats how we do it
KalamariKing: its so weird
KalamariKing: it takes me a sec
MSmits: using commas for separators is really weird for us
![]() NuclearLoremIpsum_c11d: hello word I m beginner I try to resolve the first problem . I need some help
NuclearLoremIpsum_c11d: hello word I m beginner I try to resolve the first problem . I need some help
MSmits: i mean 0.23 is ok, used to that
![]() NuclearLoremIpsum_c11d: http://chat.codingame.com/pastebin/cf77c937-7b73-4686-98f7-48a3923487cd
NuclearLoremIpsum_c11d: http://chat.codingame.com/pastebin/cf77c937-7b73-4686-98f7-48a3923487cd
KalamariKing: yeah
MSmits: 1,000,000 not ok
KalamariKing: NuclearLoremIpsum_c11d what's the first problem? that doesn't look like onboarding
![]() NuclearLoremIpsum_c11d: temperatures puzzle thanks
NuclearLoremIpsum_c11d: temperatures puzzle thanks
jacek: thats temperatures
KalamariKing: ohhhh I'm sure your code works fine, just remove the print(temperatures)
KalamariKing: also if it makes it easier, abs() returns absolute value (closest to zero)
![]() NuclearLoremIpsum_c11d: i have trouble with if x > 0 and x < max:
NuclearLoremIpsum_c11d: i have trouble with if x > 0 and x < max:
Uljahn: your else is unreachable though
KalamariKing: yeah, use > and < not >=/<=
![]() NuclearLoremIpsum_c11d: i m looking thanks you all
NuclearLoremIpsum_c11d: i m looking thanks you all
Greg_3141: that's not right, if max == min then 0 isn't necessarily correct
Greg_3141: i mean max +min == 0 oops
Greg_3141: the puzzle also demands that you print 0 if there's no input iirc. What then?
Uljahn: ye, i don't see the first input
LuisAFK: :wave:
Greg_3141: you could also simplify the for loop statement to "for x in temperature:"
LuisAFK: how can i change my email address
LuisAFK: if i previously logged in with google?
KalamariKing: when did I do this puzzle and why did I choose js
Greg_3141: it's not listed publicly so I wouldn't worry
Greg_3141: i bet you chose javascript to farm achievements or something idk
KalamariKing: I haven't done it in python tho
KalamariKing: The only time I've used smth other than python was for sc21
Greg_3141: for me, javascript is just "the language that people use because browsers use it"
jacek: starcraft 2.1 eh
MSmits: hmm my bad predictions almost always seem to be target 0 and then prediction -1 or +1
MSmits: maybe it's tanh that does this?
MSmits: I need more linear activation?
jacek: tanh should work alright
MSmits: I guess extremes are just more easily fitted
Uljahn: do you split your dataset into train/validation/test parts?
KiwiTae: for me i usually do 90% training 10% validation
Uljahn: for such a tiny TTT dataset it could be difficult to get meaningful validation i guess
jacek: overfitting here shouldnt be a matter
MSmits: i did do validation by just taking different samples
MSmits: it gives crap results
MSmits: i can fit it to like 20-30 samples succesfully, but doesn't generalize to the other states
![]() NuclearLoremIpsum_c11d: ok i m a beginner
NuclearLoremIpsum_c11d: ok i m a beginner
LuisAFK: whats better python or java??
jacek: yes
KalamariKing: MSmits what's the difference between those that are working and those that aren't
KalamariKing: hypothetical question, I don't expect you to know, but just look
KalamariKing: also since it has such high 'sure'ness is it finding a pattern that it shouldn't be?
MSmits: http://chat.codingame.com/pastebin/abad114b-2485-4b18-ae42-67b9545dc1e4
MSmits: accuracy 100% on 50 states with relu instead of sigmoid
MSmits: KalamariKing dont know really, the ones that aren't working are the ones that arent winnable
jacek: oh my
MSmits: whats weird though, the drop in cost on the third print
MSmits: is this normal jacek?
MSmits: a huge drop?
MSmits: oh btw, this is also without flipping. But without flipping it was also crap when i was still using sigmoid. Relu fixed it
MSmits: gonna do some proper testing, see how far i can stretch it with different numbers of nodes and sample size
jacek: i think this is normal on very little examples
jacek: have you tried more states
jacek: i wonder why relu would fix it though. i know sigmoid is crap but cant be that crap
reCurse: Coincidence
reCurse: Is often a valid explanation in ML
jacek: oh tomorrow's full moon
jacek: another valid explanation
MSmits: I am trying 100 samples now
KalamariKing: Sigmoid can't do negatives?
MSmits: going well:
MSmits: http://chat.codingame.com/pastebin/218c8086-5927-4de3-9455-9e03ef63243a
KalamariKing: Maybe that's why it wasn't working
jacek: :tada:
MSmits: think the 100 sample one will also reach 100%
reCurse: relu can't do negative either btw
KalamariKing: yeah I thought only tanh could
MSmits: no i just have it for input, last activation is tanh
reCurse: Not "only" tanh
KalamariKing: well not only
MSmits: you can just do linear
KalamariKing: but between tanh, relu, and sigmoid, only tanh can
MSmits: it's really converging well :)
KalamariKing: That's epic
KalamariKing: nns are awesome, when they work
MSmits: yeah
jacek: with flipping?
MSmits: no, without
MSmits: but without flipping it wasnt working with sigmoid
MSmits: so not sure if flipping would be just as good now
KalamariKing: wdym flipping
reCurse: The best part is when they work around your bugs and still perform 'good enough'
KalamariKing: oh reCurse good job with the contest, idk why it took until now to say that
MSmits: KalamariKing flipping means flipping X and O and always using the network from the perspective of X
reCurse: Thanks
KalamariKing: MSmits oh that makes sense
MSmits: it's not really necessary here to flip
MSmits: because you can tell the difference between X or O states from the number of each on the board
MSmits: so the network can learn this itself
MSmits: in oware it's different. a seed state can be both a p1 turn or p2 turn state
KalamariKing: but WILL it? it CAN, but will it
MSmits: no idea :0
MSmits: anyways, i was making it overly complex with flipping i guess, considering it's not necessary
KalamariKing: its just an inversion of the current state right?
MSmits: yeah
MSmits: but you have to be careful when using it, because what i did was i applied a move from current player's position, then flipped and did network lookup from opponent position
MSmits: but then you need to minimize the value instead of maximize
MSmits: lot sof opportunity for sign errors here
KalamariKing: yeah true
reCurse: You don't say
MSmits: for now just doing supervised learning anyways, perks of doing TTT
KalamariKing: how does mlp work btw? I'm familiar with classification (cnns, etc) and generative (rnn, lstm, etc)
KalamariKing: Done a little with actor-critic
MSmits: mlp is just input -> x hidden layers -> output
reCurse: You're mixing up architecture and outputs
KalamariKing: Right, but how does it learn
reCurse: You can do classification with a rnn
reCurse: For example
KalamariKing: Generalizing here recurse
reCurse: Too much imp
reCurse: *imo
MSmits: reCurse: "you dont say" refers to one of your own experiences with the sign errors ?
reCurse: Yes
KalamariKing: You could build a nn with a pen and paper, and do the math yourself, if you wanna go farther
reCurse: And similar math errors in e.g. backpropagation
MSmits: heh yeah it's annoying. It happened to me for ages with mcts also
MSmits: backprop is a bit harder
MSmits: not even doing complicated stuff and it's already making my head hurt
jacek: mlp is about magic of friendship
reCurse: No
jacek: :(
reCurse: Understanding autograd was the key to backprop for me
MSmits: autograd?
reCurse: That's how libraries are able to derive a gradient from your inference
MSmits: well I understand backpropagation in terms of chain differentiation
reCurse: So they need to decompose your inference into modules
reCurse: And backpropagate through these modules like a graph
MSmits: ah
reCurse: Since I'm math illiterate that's how I finally understood
MSmits: are these just the multiplication, sum and activation steps in reverse?
reCurse: Yeah
MSmits: yeah thats in the nnfs book
MSmits: I got the math, it's just really dry and hard to follow
MSmits: but cool when it works
reCurse: Yeah for me I just can't be bothered to care if I don't have the goal
reCurse: Didn't give a damn about trigonometry until I saw that's how you can move 2d sprites
reCurse: Then I got all over it
KalamariKing: wdym
reCurse: Well if you pick csb for example that's pretty much it
MSmits: well it's like that for me as well as a physicists. I think only mathematicians like the math for the math
KalamariKing: as in like move 3 units in a NNW direc, how much x and how much y?
MSmits: http://chat.codingame.com/pastebin/9b6ac484-6f2b-4c09-9199-d42c12ae8d76
reCurse: Yeah or say you're headed 1,0
MSmits: does this look right? the costs?
reCurse: You want to rotate 1 degree per frame or something
MSmits: is it just skipping around a local minimum there?
reCurse: Say like an asteroids clone
![]() oplethunder: what i the hardest script
oplethunder: what i the hardest script
reCurse: MSmits that means the noise is generally greater than the signal at that point
reCurse: Could be good, could be bad
KalamariKing: MSmits does your cost algo get smaller over time if that makes sense
XeraFiu: Hi, can you check out my post on a Clash Of Code? This is the "ASCII DOTS ART", thank you in advance :p
KalamariKing: is it coming from noise?
MSmits: yeah, well it classified all 100 W/L/D states correctly within a few % (so 0,97 instead of 1) so i am happy
reCurse: Then that's all you can squeeze out of the data yeah
reCurse: You'll never get 0.00000000
MSmits: nah i was just wondering if its normall it keeps going up and down. I guess the learning steps are greater than the error at that point
KalamariKing: but you could go from 0.00000002 to 0.00000001
reCurse: There is noise coming from stochastic gradient descent
reCurse: It's inherent to it
MSmits: ah yes, i am not batching
KalamariKing: yeah thats what I meant, are your steps getting smaller over time
reCurse: The key is you still get more signal
MSmits: KalamariKing I am not reducing my learning rate
MSmits: all that good stuff is easy with tensorflow and such. I am still doing this all by hand :0
reCurse: Don't forget reducing your learning rate can also make you overfit more
KalamariKing: oh yeah lol
MSmits: ah yes
MSmits: btw, do you use dropout reCurse? wontonimo really hates it
reCurse: I don't like it either
![]() CodeLoverboy: Good Morning!
CodeLoverboy: Good Morning!
MSmits: morning
reCurse: There are better ways to do regularization imo
KalamariKing: reCurse why tho? wouldnt it make the learning less effective over time, reducing overfit?
MSmits: probably at a cost of ...
reCurse: Overfit means you start memorizing the training instead of generalizing it
reCurse: It's very bad
KalamariKing: Yeah ik what it means and all
reCurse: So you want to be very careful with reducing learning rate
KalamariKing: I've got more theory then application so I get concepts/defs, just not why they matter ig
![]() CodeLoverboy: what you guys talking aboutz/
CodeLoverboy: what you guys talking aboutz/
MSmits: machine learning
KalamariKing: neural networks
![]() CodeLoverboy: oo
CodeLoverboy: oo
![]() CodeLoverboy: sounds cool
CodeLoverboy: sounds cool
KalamariKing: yep
![]() NuclearLoremIpsum_c11d: sound difficult
NuclearLoremIpsum_c11d: sound difficult
KalamariKing: except when it doesnt work
KalamariKing: it is lol
![]() CodeLoverboy: lol XD
CodeLoverboy: lol XD
![]() NuclearLoremIpsum_c11d: sound I can only do 1+1 :)
NuclearLoremIpsum_c11d: sound I can only do 1+1 :)
KalamariKing: why is dropout so popular? if the nodes aren't used in training, why are they there in the first place
reCurse: They are
reCurse: Just not all at once
reCurse: It's a way of not forcing the network to rely too much on too little
KalamariKing: Once a node is dropped, it gets 'picked back up' on the next rep?
MSmits: you select different ones every time you train
MSmits: yeah
MSmits: or at least a new random set i guess
KalamariKing: oh I thought once its gone, its gone
KalamariKing: ok interesting
reCurse: Here's a terrible analogy
MSmits: no the weights are just set to 0 i think
reCurse: Say you want to recognize dogs
reCurse: And then you only learn recognizing the nose
KalamariKing: msmits theoretically "gone"
MSmits: ye
reCurse: Having dropout means you'd hide the nose sometimes
KalamariKing: yeah, why would you want that
reCurse: So you need to recognize the ears too
KalamariKing: but wouldn't the two learn the same thing?
MSmits: and then you think you finally trained your network to recognize the difference between a wolf and a dog and it turns out it can only spot snow
reCurse: That was tanks and something else
reCurse: But yeah
![]() CodeLoverboy: when learning bash code script should I take the clash of code
CodeLoverboy: when learning bash code script should I take the clash of code
KalamariKing: why not
KalamariKing: clashes are more of fun and fast challenges
![]() CodeLoverboy: or path or the bot progmmarming
CodeLoverboy: or path or the bot progmmarming
![]() CodeLoverboy: my grammer
CodeLoverboy: my grammer
KalamariKing: spelling*
![]() CodeLoverboy: clashes are hard tho
CodeLoverboy: clashes are hard tho
KalamariKing: nr
KalamariKing: imo, they're pretty simple
KalamariKing: (says with a slipping rank)
![]() CodeLoverboy: im in wood or bronze
CodeLoverboy: im in wood or bronze
![]() CodeLoverboy: but im the first lvl
CodeLoverboy: but im the first lvl
KalamariKing: clashes don't have that kind of rank
![]() CodeLoverboy: of
CodeLoverboy: of
![]() CodeLoverboy: oof
CodeLoverboy: oof
![]() CodeLoverboy: im trash
CodeLoverboy: im trash
KalamariKing: nah, just learning
KalamariKing: you'll be in legend before you know it, if you want to be
![]() CodeLoverboy: Well i skipped bot programming
CodeLoverboy: Well i skipped bot programming
![]() CodeLoverboy: why
CodeLoverboy: why
![]() CodeLoverboy: just why
CodeLoverboy: just why
![]() CodeLoverboy: why is bash so not popular?!
CodeLoverboy: why is bash so not popular?!
KalamariKing: because its bash
![]() CodeLoverboy: what?
CodeLoverboy: what?
KalamariKing: its not as structured as other languages
![]() CodeLoverboy: oh
CodeLoverboy: oh
![]() CodeLoverboy: whats the eisiest one
CodeLoverboy: whats the eisiest one
KalamariKing: and afaik there's no libs
![]() CodeLoverboy: my spelling
CodeLoverboy: my spelling
KalamariKing: a lot of people say python, its sometimes practically english
![]() CodeLoverboy: oh
CodeLoverboy: oh
KalamariKing: afaik* as far as i know
Wontonimo: Warning, dropout before final output also encourages covariance. Covariance is bad. Something like batchnorm or dropout on input may have better results and less covariance
KalamariKing: oh welcome Wontonimo
Wontonimo: hey hey
KalamariKing: covariance?
![]() CodeLoverboy: how complicated is java
CodeLoverboy: how complicated is java
![]() CodeLoverboy: minecraft was built on that
CodeLoverboy: minecraft was built on that
![]() CodeLoverboy: and I want to make a game similar to it
CodeLoverboy: and I want to make a game similar to it
KalamariKing: you could really use anything
KalamariKing: I like java, its not too hard
![]() CodeLoverboy: oh
CodeLoverboy: oh
jacek: to avoid overfitting, throw more data in. [solved]
Wontonimo: hey CodeLoverboy, you may want to consider using a game engine like Unity3D which has a lot of the hard things already done for you
![]() CodeLoverboy: im dying
CodeLoverboy: im dying
![]() CodeLoverboy: ok
CodeLoverboy: ok
Wontonimo: :D jacek
Wontonimo: :thumbsup:
KalamariKing: wait ok can a neural network give 100% accuracy if you only feed it one sample thousands of times
Wontonimo: Unity3d is C#. There are some really good tutorials on their site.
Wontonimo: yes, it will easily conform to a single sample
![]() CodeLoverboy: OH
CodeLoverboy: OH
![]() CodeLoverboy: oop
CodeLoverboy: oop
Wontonimo: but that doesn't mean it knows anything other than that one sample
![]() CodeLoverboy: all cap
CodeLoverboy: all cap
KalamariKing: right
KalamariKing: but will it ever reach 100% acc
Wontonimo: for that one item? yes it will.
Wontonimo: but you don't want to do that
KalamariKing: what if you suddenly switched samples, for a second very-different sample
would the network ever COMPLETELY un-learn the original
Wontonimo: as a matter of best practice, it's best if you do that opposite and avoid training your NN on things it is already really really good at
KalamariKing: oh ofc
KalamariKing: then it will overfit
MSmits: hey wontonimo
KalamariKing: but as a thought experiment
Wontonimo: hey MSmits ! :wave:
Wontonimo: NNs unlearning is as much a problem as leaning
MSmits: I am able to do supervised learning to get 100% accuracy in 100 gamestate samples in TTT (guessing the WLD value)
MSmits: 200 hidden nodes, not sure i need that many
KalamariKing: yeah idts
Wontonimo: WLD ?
MSmits: win loss draw
MSmits: -1, 0, 1
KalamariKing: what do you do with that now though
MSmits: i rate it a succes if it is within 0.25
KalamariKing: how do you apply that
Wontonimo: omg that's awesome!
MSmits: pick a move
KalamariKing: from what?
Wontonimo: what do you mean "100 game states" ?
Wontonimo: oh, is your training set 100 items?
KalamariKing: do you 1. eval every possible move 2. w/l/d each 3. pick amongst the wins
KalamariKing: or how do you determine a new move
MSmits: Wontonimo I did a full minimax search with all known WLD solved values
MSmits: i randomly pick states from there
KalamariKing: ok that makes sense
MSmits: 100 out of 4120 i have in my set
MSmits: for 100 I get 100%... didnt expand it yet to the full set
KalamariKing: how does it do on new data
MSmits: testing that now
KalamariKing: hows it doing so far?
Wontonimo: don't train on all the them !!
MSmits: no, i know, I mean, i havent properly tested yet
KalamariKing: yeah, split to like 80/20 train/test
MSmits: I am now using a 100 train set vs 100 validation set
Wontonimo: awesome, you know your stuff
MSmits: before training it has 41% on the validation set
MSmits: so i am waiting for it to finish so i can see if that improved
MSmits: training set was always 100% so far
jacek: oO
KalamariKing: That's awesome!
MSmits: well... i know my basic stuff
KalamariKing: you're doing this all from scratch... I would say you know your stuff
MSmits: so much i dont know. I just want to get a simple thing working before tensorflow
MSmits: well yeah, people talk about it half the time and jacek shares a lot :P
Wontonimo: a classic way of using 100% of the data but not breaking the train/validation split rule, is to train at least 2 networks with different splits. Then your final bot uses a vote between all the seperately trained networks
MSmits: interesting
Wontonimo: it's classic from MNIST. "A mixture of experts"
reCurse: Ensemble networks is the term I heard
KalamariKing: that's pretty smart actually
Wontonimo: yes ensemble network ! Thanks
reCurse: Just saying in case it helps, using the right terms is usually what unlocks all the papers, so hard to find sometimes
MSmits: mmh it finished. It got stuck on one of the 100 this time:
MSmits: http://chat.codingame.com/pastebin/5a966f08-12f4-41f0-a29a-807cbc7fe2df
MSmits: not generalized yet
jacek: yeah, try to look for paper for the game of breakthrough...
Wontonimo: can you print out the validation set % after ever epoch
KalamariKing: could be that ttt doesn't have easily-recognisable patterns like images or smth
MSmits: oh, I guess I could do that
Wontonimo: you'll see if it starts to generalize then goes nuts
KalamariKing: are you using a different batch each epoch?
Wontonimo: or if it just doesn't
Wontonimo: the to imply very different issues and solutions
Wontonimo: *two
KalamariKing: the two* imply... or two* to imply...
Wontonimo: the two cases: 1 validation always low or 2 validation gets better than worse again, imply 2 very different problems
KalamariKing: oh ok
KalamariKing: makes sense, yeah
MSmits: will share this next, give it a sec
MSmits: thankfully it's training pretty fast
Wontonimo: if you can MSmits, if you can print the validation loss (but not use it for backprop) then you can compare to training loss directly
MSmits: I guess I could make this work with just hidden size increases
jacek: apparently thats what cool kids do
MSmits: yeah makes sense Wontonimo
MSmits: http://chat.codingame.com/pastebin/5b2e98c1-ea8c-422d-866f-7284508da82c
MSmits: this tell you anything?
MSmits: not finished yet but pretty clear I think
MSmits: this one will be 100% accuracy on training set, looking at the cost
Wontonimo: yeah, it learns to generalize right off the hop, then overfits
jacek: how did you choose training and validation? perhaps they are very different. increase training to 1000 samples
MSmits: both random out of 4120 TTT states jacek
Wontonimo: +1
MSmits: I can do 1000 samples,but that will be a while :)
Wontonimo: good choice
jacek: if you dont have python3 specific code, try pypy
jacek: itll be 10x faster
MSmits: meh, I just want this to work so i can move on to tf and such
MSmits: but i do print
MSmits: so python3 :)
jacek: print() will work in py2 too
MSmits: ahh ok
Wontonimo: so, it is overfitting something fierce. One way to address that is to remove the ability of the network to do that, and that means removing neurons
reCurse: I heard playing clashes help with that
MSmits: wait, are you saying dropout?
Wontonimo: no, just shrink the number of neurons in your second last layer, the layer right before output
Wontonimo: half it
MSmits: ehh, there is only 1 hidden layer
Wontonimo: great, that makes that easier
MSmits: 200 hidden neurons in it
MSmits: which is a lot i know
Wontonimo: make it 100, and double the number of training items
Wontonimo: that should have same run time
Wontonimo: please run that! I'd love to compare
Smelty: ooooh nice weekly puzzle :D
imma try it out
MSmits: allright, doing that now
jacek: yeah, not game :unamused:
Wontonimo: and are you doing mirroring, rotation to expand your training set?
MSmits: well... all of those are already in there
MSmits: mirroring and rotation wont do anything
Wontonimo: ok
KalamariKing: its a full dataset
MSmits: it's all states that can be reached if you take winning moves
![]() NuclearLoremIpsum_c11d: how much you can make if you know very well python 3
NuclearLoremIpsum_c11d: how much you can make if you know very well python 3
![]() NuclearLoremIpsum_c11d: ?
NuclearLoremIpsum_c11d: ?
MSmits: excluding the finished states
KalamariKing: NuclearLoremIpsum_c11d that all depends how much you know
Wontonimo: i was just thinking of the 200 you select randomly, expanding that to 200 x4 rotations x 2 flips
MSmits: ohh from the random set
KalamariKing: with enough libs, etc you might even make an emulator
Wontonimo: yeah
MSmits: makes sense, but why would that be very different from just taking 1600 states?
jacek: diversity in training set
![]() CodeLoverboy: hello
CodeLoverboy: hello
KalamariKing: but all of the possible states are in the training set
![]() CodeLoverboy: me back
CodeLoverboy: me back
Wontonimo: i'm guessing (and correct me if i'm wrong) that your network doesn't have any way to reuse learnings from the top right and re-apply it to the bottom left. It has to learn symetry by exhaustive example
KalamariKing: including mirrors, rots, etc
![]() NuclearLoremIpsum_c11d: kala / if you can do all the medium puzzle ? how much you can make ?
NuclearLoremIpsum_c11d: kala / if you can do all the medium puzzle ? how much you can make ?
MSmits: no KalamariKing, all possible states are in the full data, but i select a training set randomly from there
KalamariKing: thats what I meant
MSmits: Wontonimo yes it is not smart enough to apply symmetry by itself
KalamariKing: NuclearLoremIpsum_c11d again, it depends. I can make pretty cool stuff (imo) but I can't do half the medium puzzles
Wontonimo: if you are using something like convolution, with rotation operations and attention layers, then it could figure out symetry from a few examples and apply it as appropriate, but that is total overkill for CG
MSmits: re curse uses convolution
MSmits: not sure about the symmetry stuff
MSmits: but wouldn't surprise me
Wontonimo: NICE !
Wontonimo: it allows reuse of learning and can seriously speed up training if done right
MSmits: i know convolution is very useful in x-in-a-row games
MSmits: like connect 4 and others
MSmits: anything where neighbours are important
MSmits: I think it's fairly weak in oware
Wontonimo: there is a thing called 1d convolution
MSmits: yeah, left right filters
MSmits: right?
Wontonimo: right
jacek: no left?
MSmits: lol
Wontonimo: but again, i have no idea about oware
Wontonimo: heck, i haven't done any of this on CG yet. Thanks for sharing MSmits !
MSmits: no problem, half of my stuff comes from jacek though, i just built on that for TTT
Wontonimo: any chance you ran the experiment with only 100 hidden units and 200 samples?
MSmits: yeah
MSmits: its almost done
MSmits: http://chat.codingame.com/pastebin/c24d7323-ca7a-4636-b0cd-dd6928ac4b8e
MSmits: I'm happy that the 100 hidden units is still enough for 100% accuracy
reCurse: Training set accuracy is irrelevant though
MSmits: in the end, yes
![]() NuclearLoremIpsum_c11d: do you consider that you have to be a genius to do very hard puzzle ?
NuclearLoremIpsum_c11d: do you consider that you have to be a genius to do very hard puzzle ?
reCurse: That accuracy on validation set is very bad
reCurse: Goes from 33 untrained to 38
MSmits: i know
reCurse: Oops 17 untrained my bad
reCurse: Still
MSmits: oh, i have been meaning to ask
MSmits: why did you feel ttt is a bad practice thing?
MSmits: to start with?
MSmits: i know you have a reason, but you didnt say
reCurse: Because it has zero relevance to actual problems
reCurse: If you get a problem with that small of a state space you might as well brute force it
reCurse: So the lessons you learn from it are not really applicable in general
MSmits: ohh, but that's why I am doing it differently
MSmits: i was trying to train it by selfplay with ply-1 depth
MSmits: just using what states it encounters
reCurse: Even then
reCurse: That's very few states to memorize
reCurse: So you'll end up completely avoiding the topic of generalization
kovi: in my understanding
convolution can emphasize relative/local environment, not just a whole/global one
symmetry can be achieved with additional layer(s)
MSmits: well apparently I am not avoiding it, considering my current results :P
kovi: (oops...sorry...chat stuck)
MSmits: but you're right reCurse, i could solve my problem now, by just increasing my sample to most of the full data set and using enough hidden nodes
Wontonimo: I liked the results in one way, this time the validation increased and then DIDNT dive.
reCurse: Oh wait
reCurse: You are using the entire ttt states
jacek: reBless but thats exactly its good for training, you have some ground truth to compare with
Wontonimo: can you run another test?
reCurse: And hiding a few
reCurse: And expecting generalization?
reCurse: Oh boy
MSmits: sure Wontonimo
MSmits: I am using a sample of 200 out of 4120 reCurse
MSmits: and validation a different sample of 200
reCurse: Oof
Wontonimo: can you reduce your hidden layer to just 10 units, increase the sample to 2000 and also decrease your learning rate in half
reCurse: Ok your results are very good then
MSmits: only 10 !?
Wontonimo: only 10
MSmits: ok
Wontonimo: heck, make it 13 for fun
reCurse: jacek: I could see for something like connect4 where memorizing isn't possible, but ttt is way too small
Wontonimo: or 11. some reason odd numbers in NNs work well.
Wontonimo: like convolution is usually 3x3 or 5x5 not 4x4
MSmits: 2000 seems a lot, 1000 also ok?
jacek: fyi, i have 2 layers, 32x32 for uttt
Wontonimo: yeah, let's go!
MSmits: kk 11 hidden units, 1000 samples and learning rate 0.005
Wontonimo: because you have so few hidden layers, the training will be way faster
MSmits: very true
MSmits: getting better accuracy on validation
Wontonimo: once you switch to TensorFlow and use a GPU that data set will take a whole 0.5 sec per epoch or less
jacek: :tada:
reCurse: If you're not into masochism go with Pytorch
reCurse: :P
Wontonimo: hey now ...
jacek: he is, hes using TTT ~
jacek: next step would be octapawn
Wontonimo: i love TF. It's all grown up and has all the nice keras stuff now
reCurse: Grown up like weeds in the wild
Wontonimo: :P
reCurse: All over the place
Wontonimo: keep it coming, let the battle of technical tool preference commence
jacek: i prefer my own crap written from scratch
jacek: i dont trust those lib witchcrafts
Wontonimo: tbh, i haven't done any pytorch, so I really couldn't compare the two
StevensGino: hi
Wontonimo: hello
Wontonimo: :wave:
StevensGino: :D
MSmits: http://chat.codingame.com/pastebin/9019728f-b57c-45c0-b41b-b83d37584599
MSmits: overfitting way reduced, also no longer 100% on training set
MSmits: makes sense i guess, with only 11 hidden
Wontonimo: if generalization is the objective then accuracy on training set is irrelevant. But like recurse said, if you just want to memorize it all, then overfit is fine.
Wontonimo: (or did you say that. no, you said to use something else)
MSmits: yeah I get that. i just liked seeing the 100% because I wasn't sure if my network was doing its thing
reCurse: I always see 100% training as a red flag
MSmits: yeah well as long as it also performs well on your validation set, it should be ok shouldnt it?
reCurse: Sure... unless your sets have problems
Wontonimo: hey, what is the first number "untrained accuracy: 9.8 %", is that training set or validation or both?
MSmits: thats the validation set
MSmits: before doing anything
jacek: and when do you add to accuracy?
Wontonimo: wouldn't it be 33% if it was just random?
MSmits: well the targets are -1,0 or 1
MSmits: if the score is within 0,25 then I add it
MSmits: so 0,76 counts as a 1
MSmits: 0,24 counts as a 0
Wontonimo: what is -1 ?
MSmits: lost game for p1
MSmits: it's the solved status
MSmits: if you solved the game from every state, these numbers tell you the result
MSmits: I'm teaching the NN to guess that
Wontonimo: no, i mean 1.00-0.76 = 1 , 0.26-0.76 = 0 , so 0.00-0.23 = -1 ?
MSmits: 0,24 - 0 also 0
MSmits: so 0 has a wider range
jacek: -1 = -1 - -0.76?
MSmits: yeah
Wontonimo: so the targets arn't -1,0,1, they are 0,1
MSmits: no the targets are -1, 0 and 1
jacek: its not 33% because there are gaps
MSmits: i just use this for an accuracy check at the end
MSmits: it doesnt do anything
jacek: if net predicts 0.5 then it wont be added to accuracy
MSmits: thats true jacek
Wontonimo: how many outputs do you have? 1 or 3 ?
MSmits: 1
Wontonimo: ok
MSmits: i just have a delta of 0.25. Could have gone with 0.1
Wontonimo: and what value would it have to output for you to consider that it is correct when predicting -1
MSmits: -0.75 or lower
MSmits: but this is not involved in training
Wontonimo: and what's the activation function on that 1 output?
MSmits: tanh
MSmits: most guesses are like 0.99 anyways
MSmits: so the 0.25 delta was pretty random
![]() mrgf4qtbete67n: robux
mrgf4qtbete67n: robux
Wontonimo: ah, tanh has high sensitivity around 0 and low sensitivity around -.9 and .9
MSmits: yeah so maybe its good that the 0 range is wider?
MSmits: not that I intended it to be
MSmits: but as i said, this 0.25 thing is not involved in my loss function at all
MSmits: it's just something i print
![]() mrgf4qtbete67n: do you among us
mrgf4qtbete67n: do you among us
![]() mrgf4qtbete67n: http://chat.codingame.com/pastebin/73df06ce-bb21-4481-ac20-c1cd7f90c300
mrgf4qtbete67n: http://chat.codingame.com/pastebin/73df06ce-bb21-4481-ac20-c1cd7f90c300
Wontonimo: how hard would it be for you to make your network output 3 values using sigmoid activation?
MSmits: or softmax?
Wontonimo: if you can do softmax, even better
MSmits: mmh, probably pretty hard
MSmits: I am not sure how to adjust the backprop and such
MSmits: i could figure it out
MSmits: but for now i just want to experiment a bit with what i have
Wontonimo: sigmoid may be easier for you to figure out the backprop
MSmits: yeah, I might do that sometime this week
MSmits: accuracy would maybe be easier to achieve
MSmits: the reason i did a value network though is that I eventually want to use it on other games with 1 output for a value
LuisAFK: elo
MSmits: I dont see myself doing much classification
jacek: thats racist
MSmits: value combines well with mcts
MSmits: classification is racist?
jacek: :v
Wontonimo: what loss function are you using? mse mae or something else?
MSmits: eh, lemme check it's what the xor example uses :P
jacek: mse
jacek: isnt loss just for printing? does it affect backprop?
MSmits: yeah it affects backprop I think
MSmits: it's the error you're backpropagating
Wontonimo: okay, so, by using tanh and asking your network to try and return 1 or -1 for some samples you are effectively asking it to send positive and negative infinity from the hidden layer. That isn't a good thing
jacek: so how would it differ if it used mae instead of mse
MSmits: e = t - o
Wontonimo: instead, if you can make your target be .9 and -.9, that would be way better
MSmits: thats the only line i see
MSmits: error = target - output
MSmits: and thats what it backpropagates
MSmits: hmm ok
MSmits: ohh it's finally winning more too
MSmits: got 91% WR when before it didnt get over 85
MSmits: http://chat.codingame.com/pastebin/75036442-5973-423c-be4a-f828753cb914
Wontonimo: I'm not familiar with the derivative of tanh for backprop
MSmits: 67% validation on 2k samples with 20 hidden units
MSmits: 21
jacek: its just 1- tanh(x)*tanh(x)
MSmits: def tanh_prime(x): # x already tanhed
return 1 - x * x
jacek: winrate against random?
Wontonimo: we are making fantastic progress and mapping out the bias-variance curve of network size & training size vs validation results
struct: whats loserate?
MSmits: yes jacek
MSmits: thats why it was always high, because i automatically take winning moves
MSmits: and random doesnt
MSmits: but 91% is a big improvement
Wontonimo: and, good news MSmits, your validation values are mostly increasing and not suddenly falling off a cliff from overfitting
MSmits: ye
MSmits: i should try the target thingy
MSmits: 0.9 instead of 1
Wontonimo: i think it will make an improvement.
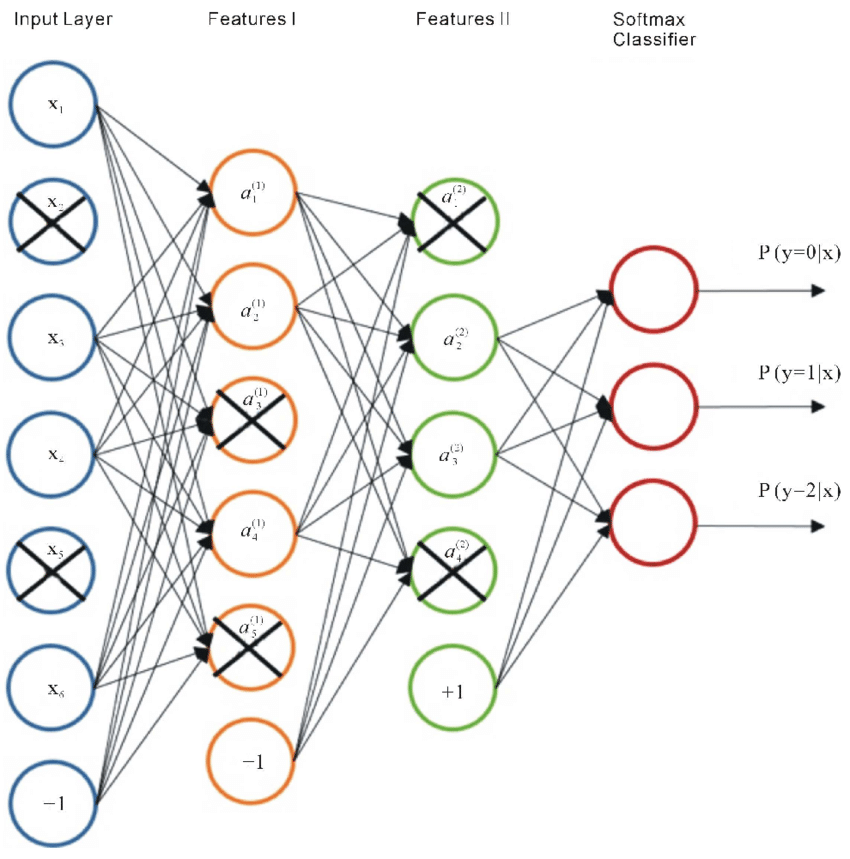
jrke: https://www.rashmeetnayyar.com/project/internal-project/featured.png the circles in this image is to doing some calculations with input right
{kind=link}
jrke: with weights
Wontonimo: how are you choosing init weights? random numbers? If so, if you can choose the same random seed from test to test you'll be able to reproduce results and not have them be so related to randomly good or bad starting weights
MSmits: well the circles can be thought of as intermediate steps between calculation jrke
MSmits: yeah, good idea Wontonimo, i will remember to set a seed when I am going to do more structured testing
MSmits: for now it's just the python random, however it does it
Wontonimo: there is a random seed in python. i think it is random.seed(x)
MSmits: ye used it before
jrke: so in NN we have to send output from circle to the every circle of next layer?
MSmits: yeah
Wontonimo: conceptually yes.
MSmits: mmh the 0.9 thingy is not doing better
Wontonimo: for that network, called fully connected feed forward
MSmits: I am more worried about the loss function
MSmits: error = target - output
MSmits: is that a good loss function?
MSmits: when i am printing the "cost" I do:
MSmits: cost += (training_targets[i]-x) * (training_targets[i]-x)
MSmits: so thats squared
MSmits: but i dont see this in the loss function of my network
reCurse: MSE is usually preferable yes
MSmits: mmh I am guessing I can't just change the error function to squaring it. I will lose the sign information
reCurse: So?
reCurse: Besides if you didn't take the absolute of the first one
reCurse: It was wrong
MSmits: hmm
Wontonimo: the derivative of x^2 is 2x. the loss is x^2, the gradient is 2x
reCurse: aka MAE
MSmits: no i wasnt taking absolute value
MSmits: I wonder what will happen if i do
reCurse: Ok so I have no idea how you got it to work at all
MSmits: haha
TENSioN: lol
MSmits: well i started from the xor example
jacek: absolute value where?
reCurse: abs(y-x)
reCurse: x = pred y = target
jacek: w00t
reCurse: That's MAE = mean absolute error
MSmits: e = t - o
do = e * tanh_prime(o)
MSmits: e is error
MSmits: i dont see abs there in the code jacek
reCurse: Yeah that doesn't look right
jacek: but thats where i see most xor examples do
jacek: i was doing NNs wrong all the time?
reCurse: Maybe there's something else to compensate for it
reCurse: But now it will only learn to output as low a value as possible
reCurse: (Or high if you do gradient ascent)
Wontonimo: gotta go. Congrats on the NN so far MSmits!
MSmits: thanks Wontonimo and thanks for the assis
MSmits: t
jrke: i am not able to understand how a network works
MSmits: it's really complex jrke. I didn't understand it in one go either
MSmits: i spent a lot of time watching videos, talking about it on chat and reading that nnfs book
jrke: mine current one is 9 inputs to func then multiplying it by weights and then output
MSmits: also I learned math at university level in a physics bachelor/master
MSmits: that kinda helps here
jrke: hmm
MSmits: not saying you have to wait 8 yrs
MSmits: but thats why it is hard
MSmits: mmh it's crap if i add abs
jacek: so, a perceptron? https://sebastianraschka.com/Articles/2015_singlelayer_neurons.html
reCurse: That makes no sense though
reCurse: It minimizes the error
reCurse: You can see without abs you'll just want to output as low as possible
jacek: what output
reCurse: The NN output
MSmits: it probably does in the context of the rest of the code you're not seeing. But I'm not gonna ask you to work through my code and Im gonna need to study more to see why it works this way
jacek: why low? output should be in (-1,1)
reCurse: Yes
reCurse: So the minimum error value is to always output -1
reCurse: That's why it's wrong
jrke: so a neuron takes N inputs multiplies each and sum up all and gives output used as input for next layer?
MSmits: yes, after applying an activation function jrke
MSmits: dont forget those
jrke: oh yes i forgot any link for that?
MSmits: i dont have a single link for that, but if you type this on google you will get tons
jrke: is sigmoid and activation same?
MSmits: sigmoid is one activation function
jacek: sigmoid is one of activation functions
MSmits: there;s also tanh, relu, leaky relu, completely soaked through relu and whatnot
jrke: so i can use sigmoid as a activation func or i need anything else?
jacek: its alright
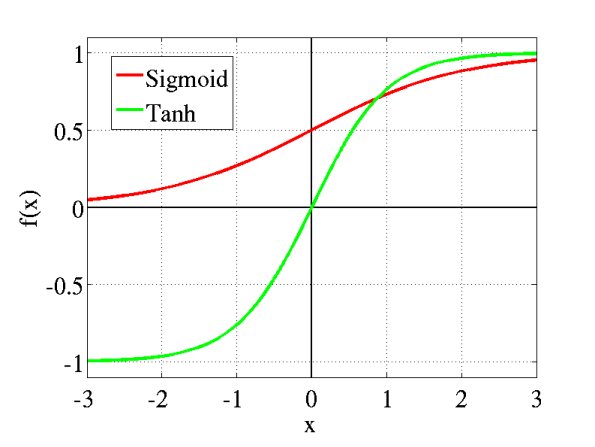
jrke: but i want -1 to 1 so tanh or sigmoid
MSmits: i use relu for input and then tanh for output, for output you generally use a separate activation function that goes together with your expected output
MSmits: tanh then
MSmits: not sigmoid
MSmits: sigmoid is 0 to 1
jrke: hmm
jrke: https://miro.medium.com/max/595/1*f9erByySVjTjohfFdNkJYQ.jpeg
{kind=link}
reCurse: Don't forget it you want -1 to 1 you can just use a 0 to 1 then *2-1 after :P
MSmits: yeah thats them
jacek: reCurse this is the way I do for all the NNs. if there is serious bug, then god have mercy on you all :imp:
reCurse: Well you obviously got something to work, I just have no idea how you compensate for that
reCurse: The bug I describe would make nothing work
jrke: whats the code for tanh i mean formula or something
jacek: tanh() its in python math and c++ <cmath>
MSmits: well my network is really simple. If you're curious you can look at it here
MSmits: https://pastebin.com/0XXnSTdH
MSmits: the error thingy is near the bottom inthe learn function
MSmits: there is no tf or pytorch or even numpy
reCurse: Oh LOL
reCurse: The tanh derivative does x*x
reCurse: You got saved by a side effect
reCurse: Hahaha
MSmits: hmm but why is it worse then when i abs it?
reCurse: Worse random initialization?
MSmits: thats possible i suppose
reCurse: No wait
jacek: hmmm
reCurse: I'm reading too fast
reCurse: Forget everything I said
jacek: who are you
reCurse: No one
MSmits: *formatting recurse data sectors*
reCurse: No that still shouldn't work
MSmits: lol
MSmits: well this is all there is, the rest of the code is not doing anything else with the input and targets
LuisAFK: *bold*?
LuisAFK: **bold**?
LuisAFK: <<bold>>?
LuisAFK: Template:Bold?
LuisAFK: _bold_?
LuisAFK: bold?
LuisAFK: `bold`?
LuisAFK: {bold}?
reCurse: Stop
jrke: LuisAFK its not discord
LuisAFK: HOW DO U STYLE
reCurse: You don't
LuisAFK: red
LuisAFK: jrke just did red
MSmits: when someone types your name it's red for you
MSmits: LuisAFK
LuisAFK: oh
LuisAFK: i see MSmits
jacek: i have some puzzle for c++ (asm?) optim nerds
jrke: just put the name it will be shown red to that player
LuisAFK: k
LuisAFK: jrke
LuisAFK: thx
jacek: https://pastebin.com/59p6JsyX
![]() CameronWatt: 1337cod3r
CameronWatt: 1337cod3r
jacek: to my intuition second function should be at most 2 times faster
jacek: but it is 6x times faster
jacek: generally instead of doing HIDDEN * 14, it does HIDDEN * 7, because i cached the pairs.
jacek: why!? oO
reCurse: Sorry I'm still at the impossible cost function
reCurse: Reminds me how I hate debugging math, even more in someone else's code
MSmits: yeah I get that
reCurse: MSmits can you get some distribution bins on your outputs
reCurse: I'm pretty sure they're all near the negative
MSmits: do you mean the predictions?
reCurse: Yes
reCurse: At the end of training with wrong costs
MSmits: but it predicts 100% and lots of them are 1
MSmits: well depending on what params i choose
MSmits: but sure
MSmits: i will bin it
reCurse: That theory would fit with the validation %
reCurse: Maybe something is wrong with your training %
darkhorse64: x is not e - o
darkhorse64: oops scroll
MSmits: training % is fine, I even printed all the board states and checked the targets and predictions manually
reCurse: I don't get it then
MSmits: best validation was 67% btw with better hyperparams
MSmits: got about 80% training with those
MSmits: better generalization
jacek: http://www.quickmeme.com/img/03/031b11a5e7a6f752ddde008e257d1070c30e10ec1c7617d3ae1a309493d75f84.jpg
{kind=link}
reCurse: I either completely misunderstand or there's something really wrong with your code
MSmits: heh, well you cant see what and I don't understand why
MSmits: so both of us are stuck
reCurse: The reason why is simple though
reCurse: The entire point is to get as low of an error as possible
reCurse: But the error is not absolute
reCurse: So target - prediction
reCurse: The lowest error value is by outputing the lowest prediction value possible
reCurse: ...Highest
MSmits: but how do you know in which direction certain weights have to be adjusted if you dont know whether you prediction was too high or too low
BlaiseEbuth: Great opportunity on the forum: https://www.codingame.com/forum/t/p-versus-np/191132 Don't miis it
BlaiseEbuth: *miss
MSmits: you lose this information if you do absolute error
MSmits: thats where i am stuck
reCurse: You know that because you know what they output
MSmits: that's true, but dont you also have to know whether this output is too high or too low?
AntiSquid: let's kaggle
MSmits: I dont have the backprop formula clear enough to be sure, but intuitively it seems that this information has to be preserved somewhere in backprop
MSmits: maybe you do absolute error in your code somewhere and conserve the sign in some other way?
reCurse: That's not how cost functions work
reCurse: I'm not sure where you're stuck
MSmits: no i believe that, I am just thinking this is not a clearly defined cost function and you can't view it isolated from the rest of the code
AntiSquid: MSmits just hand over full code
MSmits: already did
AntiSquid: ah lol
reCurse: I don't know if this helps, but look at the gradient of x*x maybe?
MSmits: thats just 2x
reCurse: Exactly, so you have your sign
reCurse: Even if the result is abs
MSmits: it's always positive though ?
MSmits: i mean the abs version
reCurse: No
reCurse: The gradient is negative on one side and positive on the other
reCurse: (Let's forget about 0 for a moment)
MSmits: right
MSmits: I got that
reCurse: So there's your sign
reCurse: It's not in the error
MSmits: but then you need to take the gradient of the absolute function, the code is not doing that either
reCurse: I'm not sure what the code is doing
reCurse: I'm just going with how it usually goes
MSmits: arent these two mistakes cancelling eachother out?
reCurse: shrug
MSmits: well as I said, you dont have to solve the problem. You've told me what to focus on and I can solve it myself
MSmits: thanks for that
reCurse: Not sure I helped actually :sweat:
MSmits: well if you're right that there's something wrong with the cost function
MSmits: then I can only make it better
jacek: i never saw any abs in xor example i encountered
MSmits: maybe xor doesnt need it somehow
reCurse: But you understand why it shouldn't work without abs?
jacek: no :shrug:
MSmits: I don't yet, but I am new, jacek should :P
reCurse: sigh
reCurse: Your optimization works either to minimize a value or maximize a value
reCurse: That value is the error
reCurse: If you want to minimize the error
reCurse: And your error is defined as error = target - output
reCurse: Minimizing the error means you want it as close to -infinity as possible
reCurse: So you want the output to be as positive as possible (not negative, my bad for earlier)
reCurse: Which obviously makes no sense
jacek: ohh so the error could go even below 0?
reCurse: Yes
MSmits: ahh ok
jacek: woah
MSmits: I am understanding this in terms of high school derivatives now :P
jacek: i didnt have derivatives in high school
jacek: (that would explain a lot, wouldnt it)
reCurse: No calculus class? Not that I remember much of it but
Astrobytes: Really? Even in physics classes?
MSmits: well depends on whether you learned them later
jacek: i only got them in university
MSmits: I actually did not learn derivatives in physics classes and i dont teach it either
MSmits: this is done in math classes
jacek: i heard a year after me they reintroduced calculus in high school
Astrobytes: We did. And in maths.
reCurse: The point with abs is it doesn't matter if you're 0.1 below the target or 0.1 above. It's a 0.1 error.
MSmits: yeah, I was thinking of it in terms of tweaking weights in the right direction, but you're minimizing the error, thats different
kovi: squared error maybe?
reCurse: That's a different one yes
reCurse: What I'm thinking now
reCurse: Is since you skipped abs and its derivative
MSmits: I wonder whats wrong with the code that it takes a bad cost function and does well with it and then does crap with a good loss function :P
reCurse: Maybe that's why it works, like you said MSmits
reCurse: But it's boggling my mind
MSmits: yeah i did not do the abs derivative
MSmits: those two things might partially cancel eachother
reCurse: I just don't know how to reason around it
MSmits: possbily network would perform better if i fix both of them
reCurse: Or might end up being the same thing
MSmits: mmh derivative of abs(x) = -1 for x < 0 and +1 for x > 0 isnt it?
MSmits: maybe i am confused here
MSmits: whatever it is, it's probably just adding a sign somewhere
reCurse: It ends up being the same thing
reCurse: OK I was a massive distraction
MSmits: yeah
reCurse: I'll show myself out
MSmits: lol
jacek: :door:
MSmits: no worries, I was wrong to just use the code without thinking anyways, it's good to open your mind to these things
MSmits: now i can start using squared error
MSmits: and know what to do
Astrobytes: Clarity is always helpful.
reCurse: Yeah I guess moving to squared error would have been difficult without seeing that
MSmits: yea
reCurse: Can't help but think I should have known this right away but I'm not kidding when I'm not fluent in math..
MSmits: I'm no expert either, maybe somewhat more fluent, but no more than the average physics student of 18 yrs ago
reCurse: Greek letters PTSD
MSmits: did you learn this all in your CS education though?
MSmits: i mean the math?
reCurse: The math of?
MSmits: partial derivatives
MSmits: for example
reCurse: Yeah I did calculus decades ago
MSmits: linear algebra
MSmits: ahh ok
MSmits: same as me then
reCurse: Promptly forgot most of it
jacek: "I was wrong to just use the code without thinking anyways" I do that all the time
MSmits: yeah we use it a bit more in later years during physics bachelor and master
jacek: and see where it got me
AntiSquid: derivatives i remember were simple, but really it's been over a decade now :D
MSmits: ye you're good with that jacek :)
MSmits: AntiSquid it's more that it's hard to keep track of the whole chain of them in this context
reCurse: I am unable to retain information if I don't have a concrete use to base it from
reCurse: Calculating derivatives of abstract random formulas, yay...
MSmits: this nnfs book does all this. "And now we take the derivative of the sum function" which ends up doing nothing
MSmits: Its good they do this, but even at their best efforts, it's almost impossible to enjoy getting through that backprop stuff
MSmits: this squarely falls into the "check it once, don't look back" category, until something goes wrong
AntiSquid: nothing complicated if you know how it works, but not if you forgot how it works :D
therealbeef: abs(x) = sqrt(x^2), so derivative is x / sqrt(x^2)
AntiSquid: oh wait mixing up integrals and derivatives, but hey overall i am sure they're simple, maybe there's a cheat sheet somewhere
MSmits: therealbeef use the chainrule too
Wontonimo: derivative of x = 1. derivative of -x = -1. derivative of abs(x) = x>0? 1 : -1
therealbeef: MSmits ?
MSmits: 0.5 * (1/sqrt(x^2)) * 2x
MSmits: = 1
MSmits: but abs is a weird function
Wontonimo: derivative is slope. You can look at abs(x) and see that the slope is 1 for positive x and -1 for negative x.
MSmits: in math you cant just square and squareroot, you'll lose information
MACKEYTH: I think you usually treat equations involving ABS as a 2-equation system when taking derivatives
reCurse: You forgot 0 = explode
MSmits: that too
Wontonimo: correct you are
MSmits: second derivative is undefined at x = 0 i guess
Wontonimo: frameworks like TF handle edge cases like that
reCurse: Um?
Wontonimo: what, pytorch don't?
therealbeef: x / sqrt(x^2) is -1 if x < 0. it's based on the chain rule
MSmits: ah right, thats true
reCurse: Hmm it does, weird
Wontonimo: (i was just guessing, but thanks for looking that up, wow)
Wontonimo: lol
reCurse: I'm surprised it handles it
Wontonimo: have you run any more experiments MSmits ? if so, please share!!
reCurse: Usually they're very pedant about correct math
MSmits: not yet Wontonimo :)
therealbeef: i guess you can add an epsilon the denominator to work around the x=0 case
**Wontonimo bites nails waiting
reCurse: Yeah but that's not pure from a math perspective
reCurse: And some people tend to hate that
reCurse: Like adding epsilons
Wontonimo: there are so many epsilons in TF... soo many
MSmits: well i just started a 3k sample with 33 hidden nodes, but at this point I am sampling half the data at least once, so it's maybe cheating
MSmits: doing a different 3k sample for training and for validation, but they're partially the same of course
MSmits: if i have time some time during the week I'll convert this to tf or pytorch or something, to do some faster testing
MSmits: need to learn that anyways
Wontonimo: tisk tisk on the overlap. Use shuffle instead of pick with replacement.
MSmits: hmm should i just sample 3k and give the leftovers to validation?
reCurse: You've essentially reduced your validation set to the samples not at all in the training set
reCurse: Yes
MSmits: ah ok
Wontonimo: shuffle(data)
validation = data[:200]
training = data[200:]
MSmits: ah thats a great way to do it, problem is that my inputs and targets are in separate array and my python skills are poor :P
MSmits: i'll figure out away
reCurse: In my experience every possible python question has been exhaustively answered twice on stackoverflow
Wontonimo: x = range(len(data))
shuffle(x)
![]() clawgod: do you need arrays in simplified monopoly?
clawgod: do you need arrays in simplified monopoly?
Wontonimo: now you have a randomized index
MSmits: yes, the hard part is asking the question right :0
MSmits: ah right
MSmits: that was what i was doing\
MSmits: i should split the index array that way
Wontonimo: :thumbsup:
Wontonimo: if you are using numpy you can do something like this
validation = data[x[:200]]
training = data[x[200:]]
if data is a numpy array
MSmits: yeah not using numpy, but basic python can do that too i bet
DomiKo: no :(
Wontonimo: validation = [data[x[i]] for i in range(200)]
Wontonimo: training = [data[x[i]] for i in range(200,4120)]
MSmits: yeah i'll loop that sht
Wontonimo: that's the comprehension way ^
jacek: no?
Wontonimo: numpy is way faster. It will vectorize operations onto cpu. The speed difference is astounding
jacek: or use pypy
reCurse: Mostly by avoiding python
Wontonimo: ^^ and ^^*2
Marchete: numpy.hsplit
Marchete: and vsplit sometimes are useful
jacek: star trek intakes, my new kink https://www.youtube.com/watch?v=5mbqppsFTeU
MSmits: well... i am currently running a 4320 training sample with the leftover 200 as validation, but gonna take hours probably :P
Thyl: Hi !
jacek: good evening
Wontonimo: how many inputs does your 3 layer network have ?
Astrobytes: lol jacek
MSmits: 27 inputs Wontonimo
MSmits: i did a one-hot version now
MSmits: so 9 x 3
MSmits: not sure if this is better than -1,0,1 with 9 inpus
MSmits: inputs, but probably is
Wontonimo: oh, so just the miniboards and not the whole 9x9
Wontonimo: you are 1/2 way to convolution dude
jacek: hmm, are you providing the inputs intelligently or it loops 27 * hidden in input layer
Marchete: tic tac toe?
MSmits: ehh Wontonimo this is basic TTT :)
MSmits: not uttt
Marchete: going big :D
MSmits: hmm
Wontonimo: i'd say you are 1/2 way to uttt
MSmits: jacek not sure what you mean
Marchete: why not connect 4?
Marchete: it's a bit bigger and solved
MSmits: I am providing inputs as [1,0,0, 0,1,0, etc]
MSmits: well the CG version isnt solved
MSmits: working on that though :)
jacek: ah
jacek: but you have 27 inputs, which 18 are zeroes
MSmits: yes, that's one hot
MSmits: well
MSmits: not exactly
MSmits: but one hot per cell :)
jacek: if you had 2d array [9][3] it would be 9 operations instead of 27
MSmits: ahh right, but if you're doing that, you probably should be using numpy also
jacek: ok. im doing that in c++ anyway
MSmits: my implementation is not smart at all
![]() CameronWatt: if clever code is hardly maintainable is it actually clever?
CameronWatt: if clever code is hardly maintainable is it actually clever?
reCurse: No
jacek: Yes
Wontonimo: ah, i didn't realize it was just ttt-u. I think your minimum hidden layer will be the number of winning configs 3+3+2=8, times 2 for each player, so 16 hidden units.
MSmits: I have 33 now
MSmits: will try some more configs over the next few days
MSmits: validation looking much better with the giant training set
MSmits: http://chat.codingame.com/pastebin/76e6e1f7-c9f7-49a1-be22-68959663c101
MSmits: about halfway now
Wontonimo: very good. And are you batching the gradient update?
MSmits: no batching
Wontonimo: and if so, what is your batch size?
Wontonimo: ah.
MSmits: batching would be difficult to do
MSmits: need transpositions and stuff
MSmits: according to jacek
reCurse: ?
MSmits: this is without tf and all that ofc, i know it's easy with tf
jacek: not difficult per se, but it would complicate simple examples
Marchete: are you doing all from scratch?
MSmits: i am working from xor example Marchete
reCurse: It's literally the same thing except you average the results
Wontonimo: literally
jacek: w00t
MSmits: allright
MSmits: good to know
Gabbek: Hello :) I've tried sending game parameters and the game is different: http://chat.codingame.com/pastebin/bf5316db-61da-4ab3-83fd-ff326c5913cf
MSmits: but as i said, i try to add one thing at a time so i dont break stuff :)
Wontonimo: it has much benefit. much
Gabbek: oh, too long message, damn - there were 2 links to replays
Wontonimo: cool cool. good idea
Wontonimo: Gabbek, I can help you not
Gabbek: I've encountered this for the first time - anyone seen something similar before? Quite surprised tbh :D
Wontonimo: i don't use replays much
jacek: the same seed?
Gabbek: yes jacek
jacek: :shrug:
MSmits: http://chat.codingame.com/pastebin/f4f79253-0585-430b-9b6e-aff940b227ee
MSmits: i accidentally set it to terminate a bit too early, but worked ok i think, high winrate too
Gabbek: nice results :)
MSmits: I should check how many losses it has because random opponent can force draws
struct: Does it lose any game?
MSmits: good question :)
struct: Yeah I think loses are also important
![]() TokenSama: this website isn't for beginners. Is it?
TokenSama: this website isn't for beginners. Is it?
struct: no
MSmits: it's for people who know at least the basics in 1 language
MSmits: they can be considered beginners
Gabbek: TokenSama depends how you define beginner - I would say you should atleast know the basics of 1 language
![]() TokenSama: okay. so where should I go to enhance my overall understanding of Python3?
TokenSama: okay. so where should I go to enhance my overall understanding of Python3?
![]() TokenSama: I like the application portion of this website
TokenSama: I like the application portion of this website
Wontonimo: those numbers are looking good MSmits !! So much progress on so many fronts. Really like that there isn't a huge gap between train and validation
![]() TokenSama: also the community is a great resource as well
TokenSama: also the community is a great resource as well
jacek: TokenSama you can try here easy puzzles like the descent or temperatures
MSmits: yeah thats good Wontonimo, it's just a bit weird to train on 95% of all states just so it can predict the other 5 % :P
amirdavids: can someone help me with a puxxle
![]() AeroFufel: @TokenSama It feels ok for anybody, even for beginners, if you start from "Practice" menu.
AeroFufel: @TokenSama It feels ok for anybody, even for beginners, if you start from "Practice" menu.
MSmits: reCurs e is right that TTT is a bit weird like that. The fraction of the statespace you need to train on is so large that you may as well memorize the entire thing
Wontonimo: yeah, but you've proven something entirely different than TTT. you've proven you can make a NN that can do okay on things it hasn't seen
![]() TokenSama: Thank you for the information you all. I hope to come back to the website as a beginner in the near future :)
TokenSama: Thank you for the information you all. I hope to come back to the website as a beginner in the near future :)
MSmits: yeah, thats cool
Wontonimo: that's the whole point of NN. well, maybe not the whole point, but it's a really really nice feature of a good working NN
jacek: hmm octapawn has bigger statespace than tic tac toe?
MSmits: I have a q-learning trinket for octapawn :)
MSmits: on trinket.io
Wontonimo: applied to a much larger problem, like SC2021, where the state space is HUGE but the concept space is much smaller, a well trained NN can convert the board into concepts then evaluate them, even it if hasn't seen that exact board
MSmits: https://trinket.io/library/trinkets/c673de5c0f click run and wait till training is done to play games
Wontonimo: I think what you have there, although not good for TTT, is a great stepping stone for a Value network !
LuisAFK: what is trinket.io
MSmits: yeah, that was the idea Wontonimo
MSmits: you can write code there and easily share LuisAFK
LuisAFK: ah
MSmits: as for statespace, i think octapawn has a slightly larger one yes
MSmits: I did a bot for 5 x 5 pawn (decapawn??) and it took half an hour to train Q-learning to the point where it saw most states
MSmits: it filled my entire browser memory
MSmits: (because table based q-learning)
Butanium: How do you evaluate the efficiency of a MCTS?
Butanium: just the amount of playout?*
Wontonimo: win rate
Greg_3141: In your opinion, would implementing an interpreter for SKI combinator calculus make for a fun puzzle?
Wontonimo: i'm just kidding. It really depends Butanium. Of course num of playouts is awesome. But some playouts are better than others.
MSmits: the only time you can compare mcts by playouts is if they all use the exact same implementations differing only in performance
MSmits: most players code a very simple mcts for UTTT. Then you can reasonably compare playouts
MSmits: but as soon as heuristics go into it, or multiple random sims per rollout or smart expansion strategies etc.
MSmits: then it doesnt work anymore
struct: yavalath is the best way to test it
MSmits: test what?
struct: Just advertising
MSmits: aahh ok
jacek: :unamused:
![]() CameronWatt: freakin python coders always handing my c# ass to me in code golf
CameronWatt: freakin python coders always handing my c# ass to me in code golf
jacek: shameless advertising of own games
![]() MitchPlease: This may be a dumb question but when Im testing this program am I supposed to have a place to input the numbers? when I run the program it just runs without prompting the input
MitchPlease: This may be a dumb question but when Im testing this program am I supposed to have a place to input the numbers? when I run the program it just runs without prompting the input
**Wontonimo just keeps looking at ttt training results and admiring it
Gabbek: struct thanks for suggestion! I'm looking to learn a bit of mcts :)
MSmits: lol Wontonimo, make some time and do this too. You're enjoying it too much to not do it yourself
struct: Gabbek yavalath is not good for vanilla mcts
struct: There are a lot of traps
MSmits: you can probably do much better
Butanium: struct : ahah thanks
jacek: MitchPlease what program (or puzzle?)
![]() MitchPlease: Temperatures! its in the easy section for loops/conditionals
MitchPlease: Temperatures! its in the easy section for loops/conditionals
Butanium: For now I'd like to see if it's optimized or not
![]() MitchPlease: it just looks like its requiring user input to fill the array
MitchPlease: it just looks like its requiring user input to fill the array
![]() MitchPlease: n = int(input()) # the number of temperatures to analyse
for i in input().split():
MitchPlease: n = int(input()) # the number of temperatures to analyse
for i in input().split():
# t: a temperature expressed as an integer ranging from -273 to 5526 t = int(i)
jacek: you read numbers from input() provided by the puzzle
![]() MitchPlease: oh the numbers are provided already
MitchPlease: oh the numbers are provided already
jacek: and you print the right answer
jacek: yes
Gabbek: struct any suggestions for learning mcts? I think uttt and connect4 are pretty good for that, anything else?
![]() MitchPlease: ookay, I thought I had to input them and couldn't get it to run lol
MitchPlease: ookay, I thought I had to input them and couldn't get it to run lol
Greg_3141: Why would you do code golf in C#? The language is designed to be as verbose as possible
struct: I think both are a good choice, but I think a mcts expert should know better
MSmits: Gabbek just keep it simple until everything works. One thing i noticed that the first time you hit a lot of bugs and mcts is a bit all or nothing and is hard to write unit tests for
struct: first time I did mcts I did it for ttt
struct: It makes it easy to debug
MSmits: yea its a good idea to do that
MSmits: it wont solve either, because it's vanilla mcts
MSmits: minimax will just solve the thing, which is counterproductive
![]() CodeLoverboy: what are you guys talking about? randon stuff?
CodeLoverboy: what are you guys talking about? randon stuff?
Gabbek: I totally agree with you MSmits - think I had this issue with my UTTT MCTS; it "sort of" worked, but I was pretty sure there was something wrong - however it worked fine for ttt; connect4 was pretty nice since it was much easier to reason about it
MSmits: what league did you get to with it?
MSmits: uttt i mean
Gabbek: think maybe I should try to work on optimization part a bit more, and then maybe switch to learning mcts solver - I have yet to do the bitboards for connect4, but they are scary
MSmits: if you got into high gold it might just be performance
Gabbek: 100ish gold
MSmits: hmm
MSmits: hard to say, if your performance is very low, then 100 gold could be a bugfree version
Gabbek: I've coded it in c# - but I've recently switched to it from python so I wouldn't say it's very performant, that's for sure
jacek: how many rollouts
Gabbek: about 3k on 2nd turn
MSmits: thats very low
MSmits: need 20k to promote to legend, give or take
MSmits: top legend has around 100k when not using too many bells and whistles that slow things down
MSmits: so likely your bot is not bugged
MSmits: good news
Gabbek: yeah, I've been reading forums and trying to figure out a bit more, but hmm - I've cached small states and did quite a lot of small optimizations, no bitboards though
MSmits: bitboards are pretty handy. Important is to keep your tree nodes small and try not to create any
BrunoFelthes: I have 15k - 20k rollouts, and i'm #1 gold, but with open book, and very fine tune at the uct tree...
MSmits: aww just a bit more BrunoFelthes
BrunoFelthes: at UTTT
MSmits: put a teccles in there
BrunoFelthes: what is teccles?
jacek: dont worry, i promoted to legend with java
MSmits: ahh we'll get you to legend if you dont know teccles
MSmits: so it works like this
MSmits: below ply 20 or so
MSmits: when you come to an empty board
MSmits: you place your mark at the same index as the index of the board
MSmits: so your opponent has to play there
MSmits: thats all
MSmits: do it on every expansion
BrunoFelthes: ahh, i do it, it is my open book :D
MSmits: allow just that one move
MSmits: hmm opening book? Thats a LOT of moves
MSmits: dont you mean heuristic?>
BrunoFelthes: eys, heuristic
MSmits: ahh ok
BrunoFelthes: yes
MSmits: I'm thinking what else you can do
MSmits: is this c++ ?
BrunoFelthes: Java
MSmits: ah well there you go
MSmits: I barely promoted to legend with C#, was very hard to do
jacek: smart rollouts? mcts solver?
jacek: tuned exploration C?
BrunoFelthes: I don't know very well what mcts solver is...
MSmits: oh, what is your exploration parameter BrunoFelthes ?
BrunoFelthes: 1.4
MSmits: and how are your wins and losses: loss = -1 and win = 1?
jacek: what do you do if you encounter final state during expansion?
MSmits: or loss = 0 and win = 1 ?
MSmits: change your exploration to 1 if it's loss -1 and win 1
MSmits: or change it to 0.5 if it's loss 0 and win 1
Gabbek: MSmits - I've just checked, my previous (what I thought a bit bugged version) had 4k, without calculating utc; the new version which uses utc and seems to be correct is about 2k rollouts on 2nd turn :(
Gabbek: hmm, interesting - I'll try to tweak exploration parameter too, just to see :)
BrunoFelthes: 5 for a win, 3 2 or 1 for a draw, depending if its me, or opponent, and depends if i'm the first or second player
BrunoFelthes: 0 for lose
MSmits: oh, creative
MSmits: then i dont know about the exploration :)
MSmits: 1.4 might be right then
jacek: huh?
BrunoFelthes: maybe i will try this -1 to 1, with exploration equal 1
Gabbek: BrunoFelthes good luck! I hope you will get to legend :)
jacek: normaly its -1,0,1 or 0,0.5,1.
MSmits: BrunoFelthes it also helped me to penalize draw if i am player 1. You are doing that too. Removing that might hurt you
MSmits: but sure, try stuff :0
BrunoFelthes: yeah
MSmits: mcts solver can help but not a huge amount, will help a little bit
MSmits: basically besides backpropagating wins and visits you also backpropagate solved values
MSmits: so you dont keep exploring nodes you already soled
MSmits: solved
MSmits: only happens when in the last 15-20 plies of the game ofc
BrunoFelthes: I'm not doing it, i just remove parent children for solved nodes
MSmits: hmm ok
MSmits: how do you "remove" children
MSmits: i cant even do that
MSmits: everything is in a big object pool and the children will still be there
BrunoFelthes: the win node is the only option available
MSmits: do you just destroy a java object?
BrunoFelthes: yes...
BrunoFelthes: not very efficient
MSmits: yeah i was thinking maybe you can speed stuff up with more object pooling, but I've heard this is hard with java
Gabbek: a surge of positive energy to try a bit more in uttt tomorrow, thanks! :D
MSmits: have fun :)
BrunoFelthes: I tried it, but i had a lot of trouble... i will try again later... I need to learn how to do a MCTS without create new objects...
Gabbek: I probably shouldn't use list for available_moves at all, right? Or just one and constantly resuse it, but an array would be better.
MSmits: I dont use lists
MSmits: while I loop over the possible moves I immediately set the children
MSmits: i dont create a list first
MSmits: object creation should be avoided as much as possible
MSmits: creation takes time and the GC cleaning it up does so as well
Gabbek: that's a very helpful tip :)
Gabbek: I've noticed insane increase in rollouts in connect4 when I've done that
MSmits: yeah
MSmits: also, if you just create a 2 million sized node pool, you can reuse that every turn
MSmits: refer to children by pointing to this massive array
MSmits: 2 million was about the max i could do in C# without resorting to weird unsafe stuff
Gabbek: I must be doing something wrong with node pool, it wasn't a big improvement for me at all
MSmits: this is because C# forces you to initialize everything
MSmits: ah ok
Gabbek: I create only 20k nodes and I don't even use all of them in UTTT :/
MSmits: well you can reuse the tree
MSmits: from the previous turn
MSmits: then you'll use more
MSmits: it's not super helpful, but helps a bit
Gabbek: I'm reusing the tree, yeah
Gabbek: I'm just advancing node parent
MSmits: ah I see
MSmits: well maybe bitboards will help
MSmits: wait
Gabbek: think I'll try to get rid of lists first
MSmits: do you keep the game state on the node?
MSmits: or just the move?
Gabbek: it was more than 80% of my time the last time I checked with profiler
MSmits: a big improvement for me was to keep the gamestate separate from the node
MSmits: and just apply the moves as you go down the tree
MSmits: only keeping the mcts statistics and move information on the node
Gabbek: my node has: http://chat.codingame.com/pastebin/ab0848ed-2aa4-4985-ac55-89c387a192f3
Gabbek: ohh, too long, whoops
struct: oh no
struct: stack list and dictionary?
MSmits: dictionary is verrrrry slow
Gabbek: so I'm doing way too heavy stuff, I see
MSmits: http://chat.codingame.com/pastebin/8f73b3b2-2ee6-45b7-87ac-07e58efc1426
MSmits: mostly simple, bonus is actually a penalty for giving away a free full move to opponent
MSmits: status is information about solving
BrunoFelthes: what is a boardIdx?
struct: the miniboard that he is playing
MSmits: yeah
Gabbek: cool, that's very helpful!
struct: whats boardState?
BrunoFelthes: and who is playing?
MSmits: i think it's just the boardint
Gabbek: guess I know what I'll be doing next :D
BrunoFelthes: at the boardState?
MSmits: boardState is the full information for a miniboard
MSmits: where the crosses and O's are
struct: why do you store it?
MSmits: and who is playing is unnecessary information
MSmits: I store it because i dont use binary
BrunoFelthes: uint16_t is 16 bytes?
MSmits: bit
struct: 2 bytes
struct: 16 bits
MSmits: if you use a binary boardstate you can easily apply moves
MSmits: it's very expensive to do in ternary
MSmits: and this is not even ternary, but something more compact
BrunoFelthes: how do you set the board in 16 bits?
Gabbek: I would like to ask you MSmits if you would like to talk about legends of code & magic one day? :)
MSmits: sure we can do that Gabbek
MSmits: BrunoFelthes ternary is one way
MSmits: picture every cell on the board as a power of 3
MSmits: cell 1 is 3^0, cell 2 is 3^1, cell 3 is 3^2 etc
BrunoFelthes: but it is 81 cells
MSmits: then if player 1 put a cross there it is 1* 3^0
MSmits: no it's a miniboard
Gabbek: it's 9 cells - it's the small board
MSmits: it's just ternary instead of binary
MSmits: so instead of 2^18 possibilities i use 3^9 possibilities
MSmits: fits in 16 bit
MSmits: but horribly slow to apply moves onto
MSmits: and it's not even what I use
BrunoFelthes: do you store only one miniboard at the state?
MSmits: yes
MSmits: the full gamestate is not on the node
MSmits: just the miniboard that was played on
MSmits: when i go down the tree, i set the miniboards
MSmits: one by one
MSmits: it's a quick assignment
BrunoFelthes: 🤯
MSmits: inline void ApplyMove()
{
vBoards[boardIndex] = boardState;
}
MSmits: full gamestate:
MSmits:
uint16_t vBoards[9] = { 0 }; static union { uint32_t bigBoard32 = 0; uint16_t bigBoard[2]; };
MSmits: I do a lot of weird sht with boardstates to have small lookupArrays
MSmits: ternary has 19683 possible boardstates if i remember correctly, but my other system has only 8692 states, so way less than 3^9
MSmits: makes for smaller arrays = better cache efficiency
BrunoFelthes: thinking about it, for MCTS, you dont need the board at the state, only the move, because at the selection phase, you always can reconstruct the state...
darkhorse64: Why is it better to update with a full miniboard rather than setting a bit ?
MSmits: because it's not a binary state
MSmits: i cant set a bit
darkhorse64: sorry, I miss the ternary part
MSmits: yeah and it's not even ternary
MSmits: it's something even more convoluted
MSmits: it's ternary with all the equivalent states pruned out
Astrobytes: I forgot about your strange UTTT
Astrobytes: Still pretty cool.
MSmits: which makes you go from 3^9 = 19683 to 8692
MSmits: so a "state" is just a unique code
MSmits: with no other properties
MSmits: and i can only transform it into another state with a lookup
Gabbek: Hello Astrobytes! How's your day?
darkhorse64: which fits into 16 bits
Astrobytes: Terrible Gabbek! I hope yours has been better! :D
MSmits: easily yeah
MSmits: and all my lookup arrays become much smaller
Astrobytes: It's a hash for want of a better term
MSmits: well i guess it's somewhat close to that
MSmits: btw, it's almost pointless to do this
MSmits: the only reason i have it this way is that this system is the onyl way to fit a full uttt gamestate in 128 bit
Astrobytes: That's why you're the only one who does it :P
MSmits: and i can use it to store states in my meta mcts very compactly
MSmits: as compact as connect4, othello etc.
jacek: or :notebook: :soccer:
MSmits: yeah it's absolutely nuts to do it this way
MSmits: can paper soccer be that small of a state?
darkhorse64: It's pointless to write a mcts with rollouts now
MSmits: because of the nn's darkhorse64?
jacek: MSmits i want to see that :v
Butanium: rollouts and playouts are the same thing?
MSmits: Butanium they can be, depending on what the person who says it means to say :P
darkhorse64: Yes. I am disgusted everytime I write a new bot. I take the lead, Jacek comes after a month and steals the show
MSmits: you mean for every boardgame
MSmits: thought you were saying uttt specifically
darkhorse64: yes
jacek: only board games with 2 players
MSmits: well yeah, for a while I was trying to keep up by counterbooking, but that takes the fun out of it too
MSmits: if you can't beat them...
Astrobytes: Note to self: only approve n player board games with n > 2
struct: dont do amazons then
jacek: btw theres volcano game waiting for approval
struct: he has NN ready
MSmits: jacek does?
struct: yes
MSmits: is it good?
jacek: on CG is just good old negamax
struct: he had 90%+ winrate vs his arena one
MSmits: oh ok
jacek: ^
darkhorse64: only my C4 still resists
MSmits: thats probably because the game is so simple
jacek: because i need to figure out convnets
MSmits: in terms of statespace
MSmits: hard to beat that with nn
struct: did re curse ever said if his STC is a NN too?
darkhorse64: 1.5 M rollouts is hard to beat
darkhorse64: but you do even better MSmits
jacek: hes booking
MSmits: I'm willing to remove the book and see how it does now. Did you improve your bot lately darkhorse64 ?
jacek: anyone want to approve it? https://www.codingame.com/contribute/view/632083262eceb06228a52291af71e1c267b8
darkhorse64: No, mcts + solver + don't play losing moves
MSmits: yeah i do the same thing i think
MSmits: resubmitted with no book
MSmits: lost to the tric in first battle :P
darkhorse64: I have tried avx2 code for smart rollouts but it's no better
darkhorse64: :popcorn:
MSmits: I have been steadily adding more book moves without using counterbooking
MSmits: so people could have improved beyond my base bot and i wouldnt know
AntiSquid: how's your NN progress ?
AntiSquid: i mean any good changes?
MSmits: not sure what the last thing was that you saw
AntiSquid: i checked chat sometime around 1 PM i think ?
AntiSquid: 8 hours ago ? :D
MSmits: http://chat.codingame.com/pastebin/55091cb3-9ac0-4028-a3a7-ca90b408d49f
MSmits: this is my current test
AntiSquid: hey that's not bad
MSmits: I just picked the whole set of minimax states as training sample except 200 states and 200 leftover states are validation states
AntiSquid: did you test in arena or something ?
MSmits: this is regular TTT
MSmits: no uttt :)
AntiSquid: i guess anything passes the wood leagues
CodeLoverboy: hello AntiSquid
MSmits: then i would have to add another account, i already have a smurf in bronze
AntiSquid: nah no point
MSmits: i just tested vs random bot
MSmits: picks the best network move except when win is available
MSmits: then it picks win
MSmits: get 96% WR with that, or did last time
MSmits: but thats includign draws which i didnt count, not sure how much it even lost
MSmits: so next time i'll be sure to count
MSmits: vs minimax bot it's a bit pointless to test, it's going to be at most 50-50, but it's going to make a few mistakes of course
MSmits: getting some losses vs you darkhorse64
AntiSquid: how many nodes did you end up with ?
AntiSquid: inputs #
hidden #
MSmits: oh my current version is 50 hidden, but works with 33 as well
MSmits: inputs 27
MSmits: one-hot per cell
MSmits: 3x9
MSmits: (sorrry jacek, you may have to resubmit)
AntiSquid: you have encoding for whether it's empty x or o ?
MSmits: yes [1, 0, 0, 0, 1, 0 .... to 27]
MSmits: thats what i mean by one-hot
AntiSquid: are you going to scale it up to UTTT or yavalath? :P
MSmits: it would be very different from this, but maybe some of it will survive i dunno
MSmits: sure eventually
MSmits: yavalath seems pointless but uttt isnt
struct: :(
AntiSquid: ya i know what one hot encoding is, i am just triggered everyone shortens it to "one-hot"
AntiSquid: https://www.kaggle.com/dansbecker/using-categorical-data-with-one-hot-encoding
MSmits: no i mean... i almost have a perfect bot on yavalath :P
Wontonimo: i shorten it to 1hot
AntiSquid: ban
Nerchio: 1h
AntiSquid: ^ block IP address
Nerchio: :fearful:
Wontonimo: i think we were suppose to use an upper case H
Wontonimo: it's weird that it isn't called N-Hot encoding
AntiSquid: i thought it's because of the 1 and 0 values you give it
AntiSquid: (binary)
Wontonimo: 10 hot encoding? Makes sense only to binary people
AntiSquid: bits encoding
Wontonimo: wait, what did i just say?
Wontonimo: softmax encoding?
MSmits: allright submit done, jacek please check leaderboard and remember my bot without book :P
AntiSquid: uttt ?
MSmits: connect4
jacek: this is so much you can do with n-tuple :(
AntiSquid: is that a jacek model you submitted, MSmits ?
MSmits: no, it's just a simple 600 line mcts
Astrobytes: Such-Warm Encoding [problem solved]
MSmits: with some reasonably smart sim rollout
MSmits: i think darkhorse does almost the same, i dont know what is different without 1 to 1 comparison of the code
MSmits: he won more than me in this submit btw
MSmits: but rps is real
AntiSquid: less bit processing power prolly
MSmits: not sure, he's pretty good at it
AntiSquid: wait, you could try to adapt your NN to connect4 first see what you get
AntiSquid: probably easiest to try to scale up
MSmits: well, the connect4 on CG is not even solved though, it's not easy at all
MSmits: there are smaller connect4's
AntiSquid: it won't matter as long as you get something that gets a few wins
MSmits: currently i am doing supervised learning for TTT, ideally it discovers by selfplay
MSmits: but thats hard to test with TTT
Chachis: hey, someone want to play? https://escape.codingame.com/game-session/GxE-as1-zX8-Q5h
AntiSquid: anyone tried atomic chess btw? it's so weird .
CodeLoverboy: whats that?
![]() kan181: when you capture a piece the board explodes
kan181: when you capture a piece the board explodes
struct: I think its solved AntiSquid
![]() kan181: "Although the advantage is significant, no attempts to prove a win for White have been successful."
kan181: "Although the advantage is significant, no attempts to prove a win for White have been successful."
struct: or maybe its another variant
struct: anti chess
![]() kan181: horde?
kan181: horde?
struct: The variant where enemy is forced to capture
struct: ok maybe i dont know what anti chess is
darkhorse64: you won 7-6 MSmits. You don't need the book
MSmits: ohh ok
MSmits: yeah the last few battles were better i guess
MSmits: it had a bad start
MSmits: but I like the book :(
darkhorse64: With the book, it's even more
MSmits: it's huge now thanks to 10 cores trying to solve the game
MSmits: 31 kb
MSmits: might need to start compressing
darkhorse64: I should resubmit because my games are aging a lot
MSmits: aging?
struct: do it you will stay 2nd at worst case
darkhorse64: your played disapear with time
darkhorse64: *games*
darkhorse64: fire
MSmits: you mean you just see other submits
darkhorse64: yep, the most recent ones
struct: you both submited o.o
darkhorse64: I wonder if the old games are still in the stats
MSmits: i got a loss with the full book power darkhorse64
MSmits: last book move on ply 11, quite deep for non-counter book
MSmits: means you're playing well
darkhorse64: 170K rollouts second turn
darkhorse64: helps a lot
jacek: :s
darkhorse64: I wish avx2 helps more. It's a pity such unreadable code does not perform better
MSmits: ah, you're defining it differently
MSmits: Rollouts: 33408
MSmits: but that's with all children
darkhorse64: yes
MSmits: so mine is, I guess? like 200k?
MSmits: not sure
MSmits: also depends on the cpu you get
darkhorse64: 4 points lead :sob:
jacek: where
darkhorse64: Now decreasing. C4
jacek: :bomb:
jacek: 4+ points sounds like me in bt before the reBless :unamused:
darkhorse64: :elephant:
jacek: hmm https://img-9gag-fun.9cache.com/photo/aQomRzK_460svav1.mp4
struct: do uttt with this
MSmits: http://chat.codingame.com/pastebin/19ca45e7-2aed-4ff9-aa1b-01bea51e648e
MSmits: you asked about losses struct
darkhorse64: :book: wins :elephant:
struct: thanks
struct: if you train it against minimax will it only learn how to draw?
jacek: noice
MSmits: it's not training against anything now
MSmits: it's just supervised learning
MSmits: so the states are labeled by a perfect minimax and then learned
MSmits: but it's not perfect, you can tell from the validation
jacek: and we agreed the NN works like it should? not that weird abs eh?
MSmits: somehow it just does't lead to losses
Wontonimo: :thumbsup:
MSmits: jacek it works as it should, but re curse might have had a point if I had been using a different loss function
MSmits: I need to get into that to be sure
Astrobytes: I lost the conversation somewhere, you're NNing C4 now or that's separate?
MSmits: that was AntiSquid's idea
MSmits: this is still just TTT
Astrobytes: And your C4 submit was just your regular bot?
MSmits: i submitted twice, once without book and once with book
darkhorse64: Astrobytes: comparing book vs no book
darkhorse64: book smashes teapot
Astrobytes: Ah, gotcha. Thanks darkhorse64
jacek: C4... lets recall the memes once again https://9gag.com/gag/aeDNdGv
Astrobytes: lol
MSmits: i love that one
Astrobytes: I will resist looking, I always read them all.
Gabbek: haha, that's a great one, jacek
MSmits: it's really perfect, no idea how to get a dog to do that, or is it doctored somehow?
MSmits: the timing of it kicking over the board is great
MSmits: anyways, gotta get some sleep. Gn
darkhorse64: gn
Gabbek: gn
Astrobytes: gn MSmits, Gabbek
Astrobytes: Wait a sec, MSmits never saw the replies to that C4 post?
jacek: :upside_down:
MSmits: i saw it before, the first time jacek shared
Astrobytes: What happened to sleep eh
MSmits: hey i was getting there
MSmits: apparently my dog needs to pee
jacek: need more chloroform
MSmits: that wont stop it peeing
Astrobytes: Worth a go
MSmits: yeah it's gonna go no matter what
ZarthaxX: hey
MSmits: so i am taking it outside, then sleep :P
struct: hi
Astrobytes: Hey Zarthy, structy
jacek: really, how can you meme connect4, its so random
ZarthaxX: he guyssss
ZarthaxX: hey*
Astrobytes: he man
Astrobytes: By the power of Greyskull, how does your day go ZarthaxX?
ZarthaxX: oh gooodd
ZarthaxX: just finished 2 things for uni
ZarthaxX: sent a cv yesterday for a potential teacher place at uni
ZarthaxX: i dont think i will be able to do it anyway
Astrobytes: But they might train you on the job no?
Marchete: another teacher?
Marchete: my god that's a plague!
Astrobytes: In the specific-teacher-parts. I mean, you have the knowledge and can explain very well so...
struct: I think he can be a good teacher
ZarthaxX: nah
ZarthaxX: no training
Astrobytes: Defo struct
struct: He taught me well
Marchete: "i dont think i will be able to do it anyway" -> Impostor's syndrome
ZarthaxX: it's a simple job
Marchete: most people are plain stupid
Astrobytes: Marchete you're correct
ZarthaxX: thing is uni is on crisis, because teacher count is decreasing
jacek: if you dont know it, teach it
ZarthaxX: so many students are trying to replace those to help
ZarthaxX: and well also because its nice
ZarthaxX: struct <3
struct: I dont think I can finish stc
Astrobytes: We have this problem over here too ZarthaxX, but there is no incentive for anyone to teach
Astrobytes: So it's ISTC?
Marchete: don't you have 2 month vacation on summer?
struct: its not easy to be a teacher
ddreams: I was considering going into teaching as well... then I looked at the possibilities and challenges
ZarthaxX: what is the cause in your country astro?
MSmits: allright got back from emptying dog, to say hi to ZarthaxX. Good luck with the teaching thing, hope you get it
ZarthaxX: here it's basically economic
ZarthaxX: software industry pays way too much lol
Marchete: as all in argentina...
ZarthaxX: thanks smito :)
ddreams: exactly.. also I love to travel, and I can work remotely
ZarthaxX: but anyway all the people that tries get it
Astrobytes: ZarthaxX: Terrible pay, huge class sizes, stupid curriculum, no support, I could go on
ZarthaxX: i guess its kind of same here
ddreams: I've also found that the enjoyable parts of teaching can be found by mentoring
ZarthaxX: i wanted to teach the subject that i loved most and was like one of the worst :D
ddreams: *can be had
ddreams: Which subject is that?
Marchete: bears
ZarthaxX: algorithms 3
ZarthaxX: the laboratory part
Marchete: ahh, that too, yes
ZarthaxX: where you code graph theory stuff, and the projects are related to optimizing, and can even put bot programming on it :)
Astrobytes: Teaching is very enjoyable. Trying to teach in amongst a mountain of paperwork from enforced bureaucracy, poor pay, no teacher or student support, crumbling (literally sometimes) schools is nto
Astrobytes: *not
ZarthaxX: huh
ZarthaxX: yeah i doubt that happens here
ZarthaxX: most of the students that get into teaching are super bad tho
ZarthaxX: painful to watch :(
ddreams: At higher levels of uni the teachers seem to have fun again
ddreams: Small classes of smart and motivated students
Astrobytes: I have only 1 friend left who is still a teacher and he recently became one. All others left in the past 5-10 years (I knew at least 12-13 who were teachers)
Marchete: I thought Scotland would have better education
Astrobytes: Marchete: We are under English rule
ddreams: I took mine in Australia, was very good
Marchete: I thought UK* would have better education
Astrobytes: UK just means: England ruling the other countries
struct: is england education even good?
ZarthaxX: wow huge decrease Astrobytes
ZarthaxX: that's so bad
Astrobytes: If you have the money and the right connections struct, then yes
struct: so the answer is no
Astrobytes: It's not a yes, it's not a no
Astrobytes: There are amazing people out there trying to do their damn best in a climate of 'rich go first'
Marchete: with money all is simpler
Astrobytes: But when it comes to England (aka UK) the class system comes first.
ddreams: time to improve my fall challenge rank
Astrobytes: If you have 2 people going for a place at Oxbridge (Oxford or Cambridge) - or indeed any big uni - if one candidate is from a paid-for school in a posh area and the other is from a poor area and a (statistically) crap school - guess who's gonna get the placement.
Astrobytes: And that's before we even start on Eton.
ddreams: did all of you take a formal education?
Astrobytes: Later in life but yes.
Astrobytes: (for me)
Marchete: so normal business, meritocracy is a lie
ddreams: same, later
Astrobytes: Meritocracy does not exist Marchete, except perhaps in social groups
Marchete: that's what I'm saying, uni or work, it's the same
Astrobytes: Aye
Astrobytes: Get plutocratic or die tryin'
Astrobytes: /s
![]() YoloTheBear: Should I try to implement Bezier Curve or PID Controller, which one is more useful to knwo
YoloTheBear: Should I try to implement Bezier Curve or PID Controller, which one is more useful to knwo
Astrobytes: Both are useful. But you're doing CSB
![]() YoloTheBear: csb?
YoloTheBear: csb?
struct: coders strike back
![]() YoloTheBear: Oh. The PID or Bezier is for the Mars Landing Optimization
YoloTheBear: Oh. The PID or Bezier is for the Mars Landing Optimization
jacek: id say use PID
![]() YoloTheBear: Cool cool , thanks
YoloTheBear: Cool cool , thanks
jacek: or GA :thinking:
Astrobytes: Oh right. Well, multiple approaches for sure. I did GA but PID could work for sure.
sprkrd: they're not mutually exclusive, actually
sprkrd: you could use GA and PID
Astrobytes: This is true, yes
sprkrd: (GA to tune the PID gains dynamically)
Astrobytes: Yeah I get it. I wonder how many people have taken that approach?
Astrobytes: Seems pretty interesting.
ZarthaxX: would love to make that work lol
ZarthaxX: hate ml3
sprkrd: Actually, technically speaking GA would be ill-suited for the task because its a continuous optimization problem, something like ES (Evolution Strategies) should work better
sprkrd: it's*
Astrobytes: Almost anything is better than a rolling horizon EA
Astrobytes: (as you find them on here)
Astrobytes: I think there are a multitude of approaches to tackle it, I do not pretend to know which is optimal.
Astrobytes: *standard RHEA that is
sprkrd: Sure sure, I was speaking of the GA/PID interaction, not about GA in general. Since the PID gains are continuous, something like ES should be better.
Westicles: Seems like the old school guys aren't moderating much these days, some unusual ones are getting through
sprkrd: Unusual ones?
Astrobytes: Contribution-wise Westicles?
Westicles: First the ASCII art one with unicode, now a project euler type (prime fractals in pascal's triangle)
Astrobytes: sprkrd: I think there's a lot of value in experimenting with different approaches
sprkrd: indeed
sprkrd: I happen to like the prime fractals problem quite a bit
sprkrd: But that one hasn't been accepted yet, right?
Astrobytes: It has. Was trying to find it lol
Westicles: https://www.codingame.com/training/expert/prime-fractals-in-pascals-triangle
sprkrd: Really? Last time I saw it it had 0 votes
sprkrd: oh, that's cool
Astrobytes: I've been absent past few days for the most part so not sure on the vote uptake
struct: I rarely check contributions tbh
Astrobytes: I look for multi or solo game mostly
Astrobytes: Westicles: what's up with the prime fractals one? (briefly please)
sprkrd: given a row, a column, and a prime p, the task is to compute the amount of numbers non-divisible by p up to the given row and column of the pascal triangle
Westicles: Nothing serious, just usually someone will reject ones like that based on too much math
Astrobytes: Ah right. Was gonna say it looked fine to me.
sprkrd: oh, you meant it like what's wrong with it
Astrobytes: Yeah sprkrd
Westicles: Maybe the environment is right for me to break out a million digits of pi once more :P
Astrobytes: lmao
Astrobytes: When I don't know something maths-wise in regards to a puzzle (or several - I try to do a few at a time even if I don't do many) I go off and either brush up on it or learn
Astrobytes: Zeno's BBP puzzle sent me down a right old rabbithole
Wontonimo: learning math for fun, you guys are nerds
Wontonimo: and i'm so glad i found you
Astrobytes: Excellent!
Now send ME tacos :P
Wontonimo: that's not how it works
ddreams: I'm afraid they'll be unappetizing when they arrive
ZarthaxX: haha
Astrobytes: It's about contacting local restaurants! Not mailing.
ddreams: My neighbor runs a mexican restaurant.. I could ask him
ddreams: Definitely a local restaurant
Astrobytes: Is he Mexican?
Wontonimo: Have I gloated in my GrandMaster achievement lately? They'd be labeled, sent by a CG GrandMaster. You'd be the envy of everyone around who isn't staying at home because of covid
ddreams: His name is Jose
Astrobytes: ...
Wontonimo: how about orbital class taco cannon delivery
Wontonimo: https://www.nextbigfuture.com/2009/10/orbital-gun-launch-systems-light-gas.html
Wontonimo: The ram accelerator is a chemically powered hypervelocity mass driver that operates with intube propulsive cycles similar to airbreathing ramjets and scramjets. The launcher consists of a long tube filled with a pressurized gaseous fuel-oxidizer mixture
Astrobytes: I want my tacos delivered in green-shrouded cylinders that come from Mars tbh
Wontonimo: great for launching taco to anywhere in the world within 17 min
ddreams: still warm from reentry too
Astrobytes: That's definitely what the Martians were using in WotW
ddreams: you could just send it uncooked
Westicles: This great taco placed opened less than 200 steps from my couch. Starting to get sick of them actually
Wontonimo: and reentry heat would do the rest
Wontonimo: great thinking ddreams
ddreams: Is that another imperial unit of measurement?
Astrobytes: That's a pathfinding issue Westicles
ddreams: Five furlongs and 39 steps from my couch
Astrobytes: 39 Steps hehehe
Wontonimo: no you've got to write it properly 5Fg39f
Wontonimo: wait, it's imperial so it has to be smallest first like so 39f5Fg
Astrobytes: Ewww. Grim.
Wontonimo: anyone play Spaceflight Simulator? It's an android game
ddreams: nope
Wontonimo: speaking of orbital launch, I was thinking something like Spaceflight
Simulator may make a nice optimization game on CG
ddreams: played a bit of bitburner lately
ddreams: a programming game
Astrobytes: Westicles: I think an A* or maybe a Dijkstra could work in your fast food mission. It would of course be manually updated every day but hey. Pathfinding is pathfinding
ddreams: https://danielyxie.github.io/bitburner/
Astrobytes: Have you played any Zachtronics games?
ddreams: Several
![]() oplethunder: supe nerd
oplethunder: supe nerd
Westicles: lol Astrobytes. The real problem is the 400 step pub went bankrupt
Wontonimo: those look cool Astrobytes
Wontonimo: that is a real shame Westicles
![]() oplethunder: ople thunder i a godddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddd
oplethunder: ople thunder i a godddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddddd
Wontonimo: how can a pub go bankrupt
Astrobytes: Westicles: Goddamn it. BFS it is
Wontonimo: BarFirstSearch
Astrobytes: Bye bye oplewhateverhewascalled
ddreams: at the end of the night you can bogosearch your way home
Astrobytes: Wontonimo: My cats are pretty good with search algos and CS theory, they are specialists in Monte Carlo Tail Search, Bird-First Search and Human-Cat Interaction.
reCurse: Sounds like way too much work for a cat
reCurse: I call CS
Wontonimo: lol >D
Astrobytes: OK, they might be bad at HCI
Astrobytes: But I stand by that statement
Wontonimo: how many cats you got?
Astrobytes: 2 too many
Wontonimo: oddly non-specific. Since I suspect you think that 5 is reasonable, that means you have 7. That's a lot of cats, seek help.
Astrobytes: That ople guy is wrecking my PMs with uuuuuuuus
Astrobytes: I have 2 :D
struct: 5 cats is reasonable?
struct: o.o
Astrobytes: Never go above 2.
Wontonimo: 3 is the first step to insanity
Wontonimo: I had 1. Then we got a dog.
**Wontonimo lets the incomplete info sit for a while
Wontonimo: the cat ran away. The dog is a good dog. Never hurt no-one
Wontonimo: cat was racist
Wontonimo: speciesist
Wontonimo: i miss that cat
Westicles: When I was 4 it was over 100F out, so I put the cat in the deep freeze to cool it. It ran away and never came back
ddreams: smart cat
Wontonimo: i don't know why i find that so funny
ddreams: probably a serial killer
Astrobytes: Met one of those once or twice. Insisted on mowing downd fields of the poor plants.
Astrobytes: Oh... *serial*
Astrobytes: My bad.
Wontonimo: haha
Astrobytes: Anyway. See you all tomorrow-ish.
Wontonimo: later
Wontonimo: i'm out also
ddreams: Eat your serials
ddreams: night night
![]() WolfDW: hi
WolfDW: hi
![]() Zvoov: send code pics
Zvoov: send code pics
struct: gn
![]() WolfDW: gn
WolfDW: gn
Smelty: g' afternoon
![]() Lvatource: gn
Lvatource: gn
![]() Lvatource: hello
Lvatource: hello
![]() HurricaneKatrina: Hi!
HurricaneKatrina: Hi!
![]() mathiimag: hi
mathiimag: hi
thomasgonda3: hey i got in the top 2% for optimization and didnt get the achievement for it
Smelty: achievements might be slowed down
ZarthaxX: thomasgonda3 you may need to wait for the next server rank recalculation
ZarthaxX: :(
ZarthaxX: that's in 24 hs, because it just happened
Smelty: yep
Nanosplitter: Is it possible to import a library from pip?
Nanosplitter: Guessing not but wanted to make sure
![]() Skullteria: def no
Skullteria: def no
Nanosplitter: Figured, rip lol
Smelty: e ded chat
![]() Fitzgerald_L: ay
Fitzgerald_L: ay